My first move wasn’t a textbook
I’m preparing to sit Anthropic’s Claude Certified Architect – Foundations exam, with a goal of taking it by the end of this month. The first thing I did to prepare was not open a course or a textbook. It was get an agent to fix the plumbing on my study tools.
I’d built a set of study materials in NotebookLM — audio walk-throughs, infographics, flashcards, a quiz bank — and the session that connected my tooling to them had quietly expired. The command-line tool that pulls those artifacts down kept bouncing me to a login screen. So before I studied a single domain, I spent twenty minutes in Claude Code: reading the authentication code to find where the saved session was failing to refresh, writing a small script that re-saved it without the manual step that was blocking automation, and pulling my own materials back down.
It struck me, sitting there, how on-brand the moment was. I was using an AI agent to repair the AI tools I’d built to study for an AI architecture exam — hosted, as it happens, on Anthropic’s own learning platform. Using the thing to learn the thing.
That loop is the reason I’m writing this in the open. This is the first in a short series on how I’m preparing — what the exam actually asks, the two study tracks I’m running at once, and what’s clicking versus what isn’t. I’m writing it as I go, before I know the result.
The exam that wasn’t open to me
There’s a part of this I didn’t expect to be writing about: until recently, I couldn’t have sat this exam at all.
The certification path was gated in a way that a small, founder-led firm couldn’t clear. Not on merit — on size. It’s a quiet kind of barrier, the sort that tells you a credential exists but isn’t quite meant for an operation like yours yet. You can be doing the work every day, shipping the thing the exam is about, and still be standing on the wrong side of a threshold you didn’t set.
That gate lifted a few weeks ago. The path opened to firms like mine. The first thing I did when it did was give myself a target — end of the month — and start preparing in earnest.

I’m dwelling on this because it reframes the whole exercise. This isn’t a box-checking ritual for me. It’s the first time the formal marker for work Prism already does has actually been within reach — and I’d rather earn it now, while it’s fresh, than treat it as someday-maybe. The barrier lifting is what turned "I should get certified eventually" into a target I set for myself this month.
Why the credential, and why now
Prism AI Analytics helps operators put autonomous agents to work against the systems their business actually runs on — codebases, customer data, billing. That work demands a specific kind of judgment: not whether an agent can do something, but whether it should, where it breaks, and what has to be true before it touches production.
The Claude Certified Architect – Foundations credential validates exactly that judgment. It isn’t a participation badge. It tests whether a practitioner can make informed tradeoffs building real solutions across Claude Code, the Claude Agent SDK, the Claude API, and the Model Context Protocol — the same surfaces Prism builds on every day. Earning it puts a verifiable marker under work the firm already does, and keeps my own hands on the tools rather than narrating from a distance.
I came up through business intelligence and data engineering — years of it, including time at one of the four largest U.S. banks. The rigor I built there is real: schemas, lineage, reproducibility, the discipline of data you can defend to an auditor. But operating agents in production is its own domain, with its own failure modes, and I’d rather be measured against it than assume my old rigor ported cleanly. It mostly doesn’t. That gap — between being expert in an adjacent field and being tested on this one — is a recurring theme in this series.

What the exam actually rewards
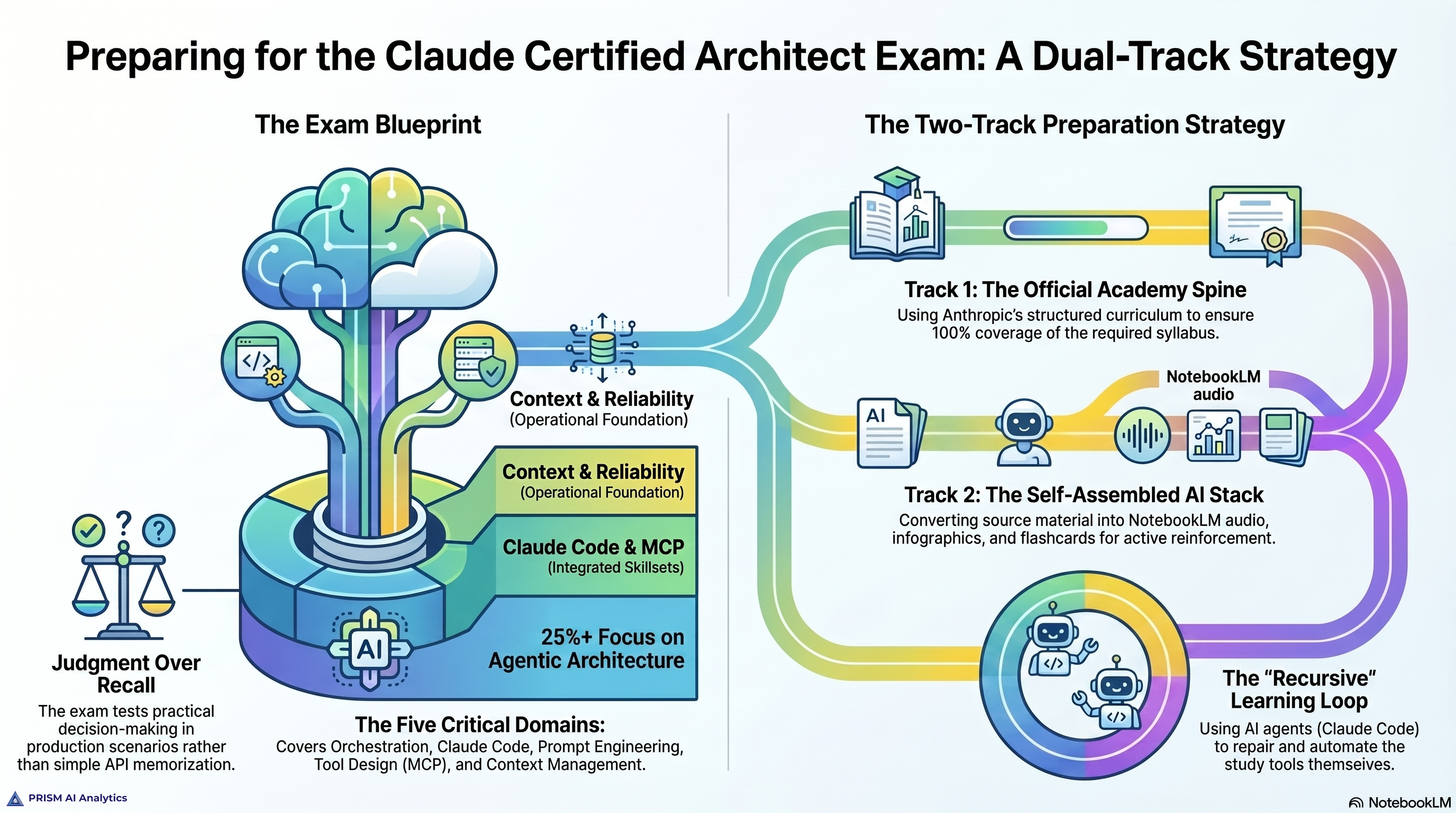
The exam is graded on a scaled score, with a clear passing line — and what matters more than the number is where the questions live. They’re drawn from realistic production scenarios: a support agent that has to resolve most tickets on first contact, a research pipeline coordinating several agents, a data-extraction job that has to survive messy real-world inputs, Claude Code wired into a team’s existing pipelines. The questions reward practical judgment over recall. You’re not asked to recite an API signature; you’re asked what you’d do when an agent skips a step it was supposed to take, or when overall accuracy looks fine but masks a failure mode hiding in the hard cases.
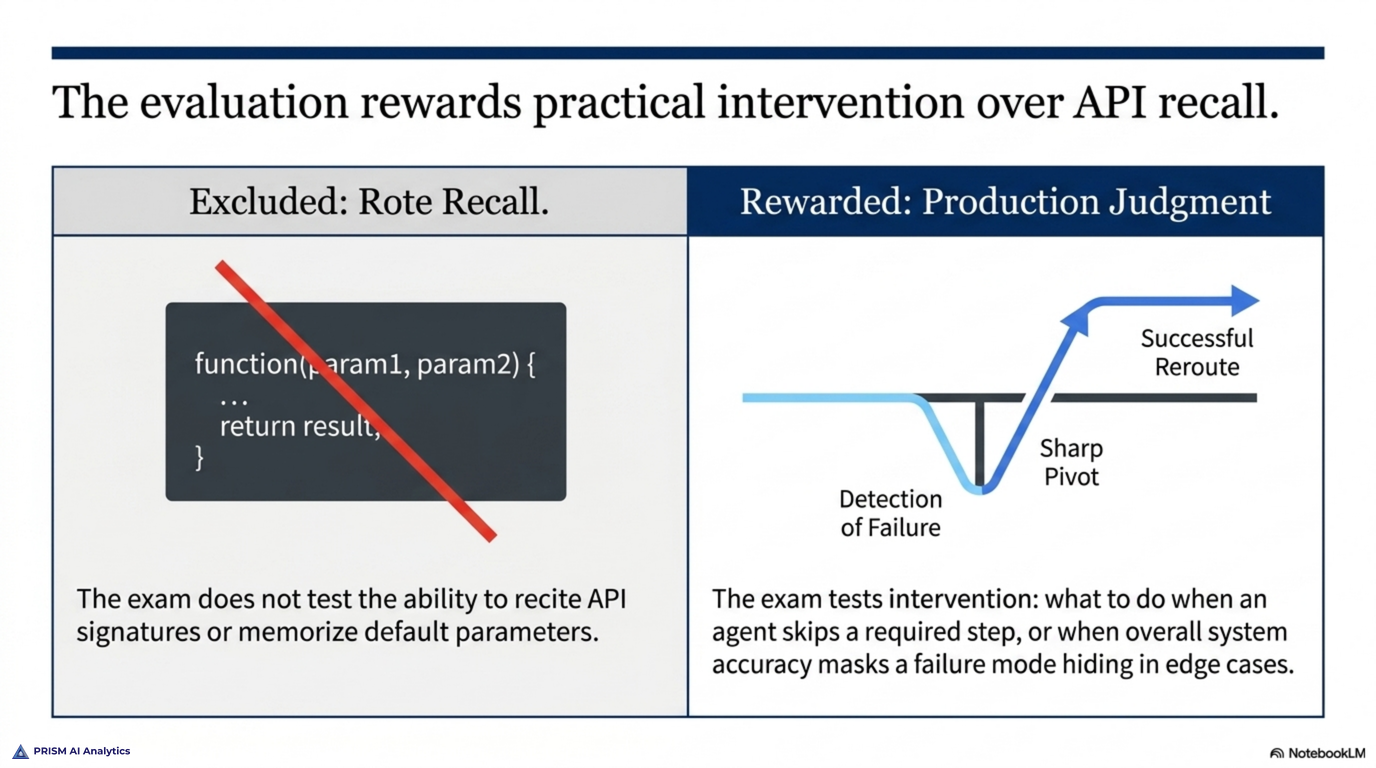
The scored content spans five domains: agentic architecture and orchestration, Claude Code configuration and workflows, prompt engineering and structured output, tool design and MCP integration, and context management and reliability. They aren’t weighted evenly. Agentic architecture and orchestration carries the most — more than a quarter of the exam on its own — and it’s the domain the others hang off, because orchestration decisions cascade into how you design tools, manage context, and keep a multi-agent system reliable.
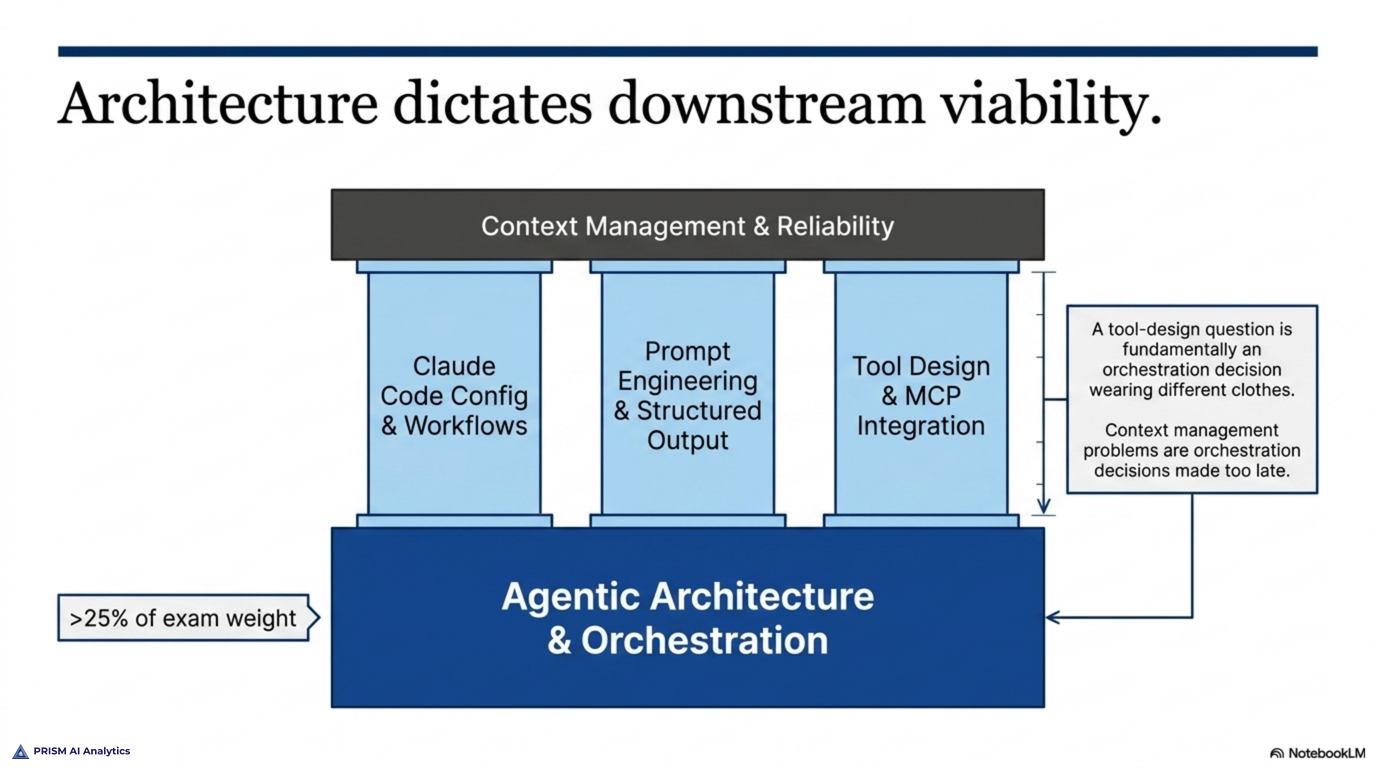
Seeing that shape changed how I’m spending my preparation. Rather than studying five domains as five separate stacks, I’m anchoring on architecture and pulling the others toward it: a tool-design question is really an orchestration question wearing different clothes; a context-management problem is usually an architecture decision made too late. Studying for the weighting, not just the syllabus, is its own small lesson.
Two tracks, running at once
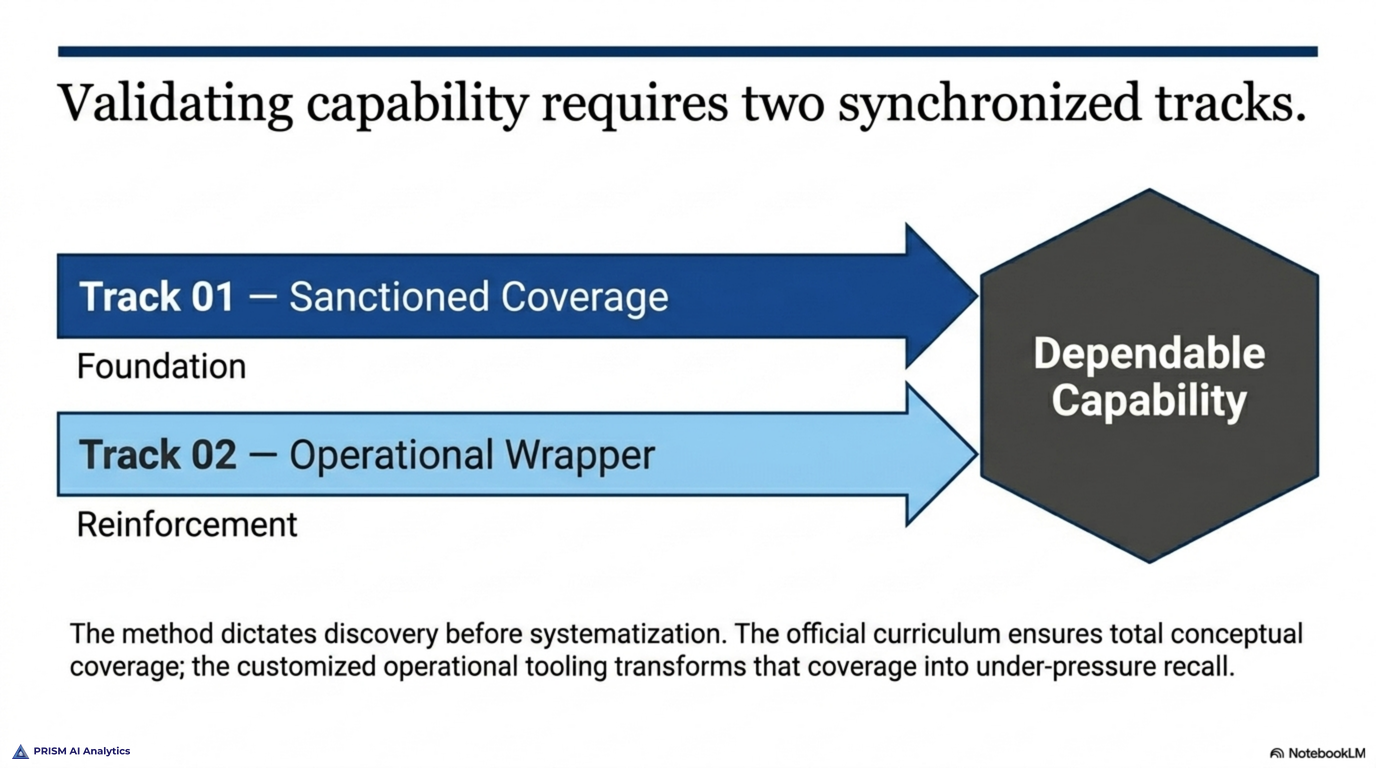
I’m preparing along two tracks, and the interesting part is how they reinforce each other.
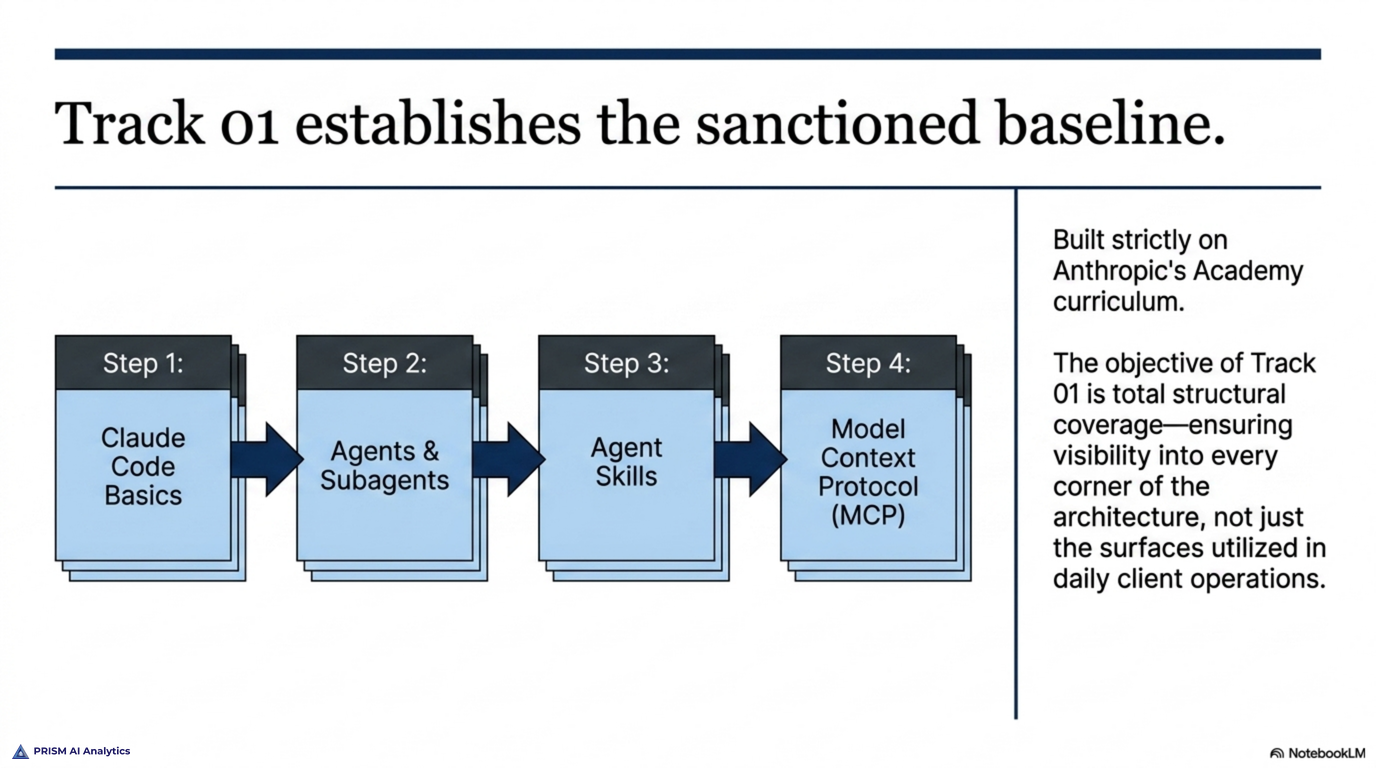
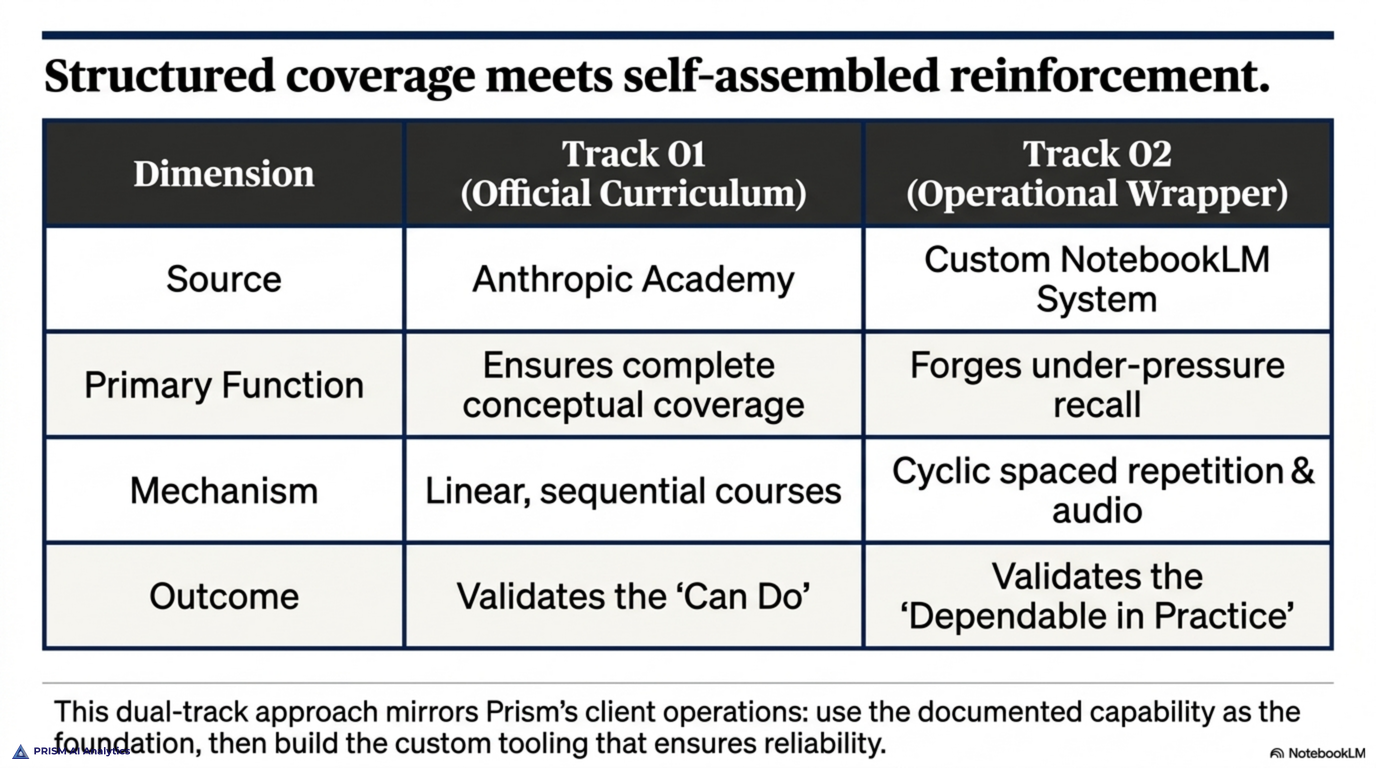
The first is the official path: Anthropic’s Academy curriculum. It’s the sanctioned, structured route, and it’s the spine of my preparation — courses on Claude Code, agents, subagents, agent skills, and the Model Context Protocol, each building on the last. I’m most of the way through it now, on my last required course. The curriculum’s job is coverage: making sure I’ve actually seen every corner of the material, not just the parts I use daily.
The second is the track I built myself. I took the source material and turned it into a study system in NotebookLM. Audio overviews I listen to away from the desk, so a domain gets a second pass while I’m walking or driving. Infographics that compress a whole domain onto a single page, which is how I find the gaps — if I can’t reconstruct the one-pager from memory, I don’t know it yet. And flashcards and quizzes for the spaced repetition that actually moves recall from "I recognize this" to "I can produce this under time pressure."
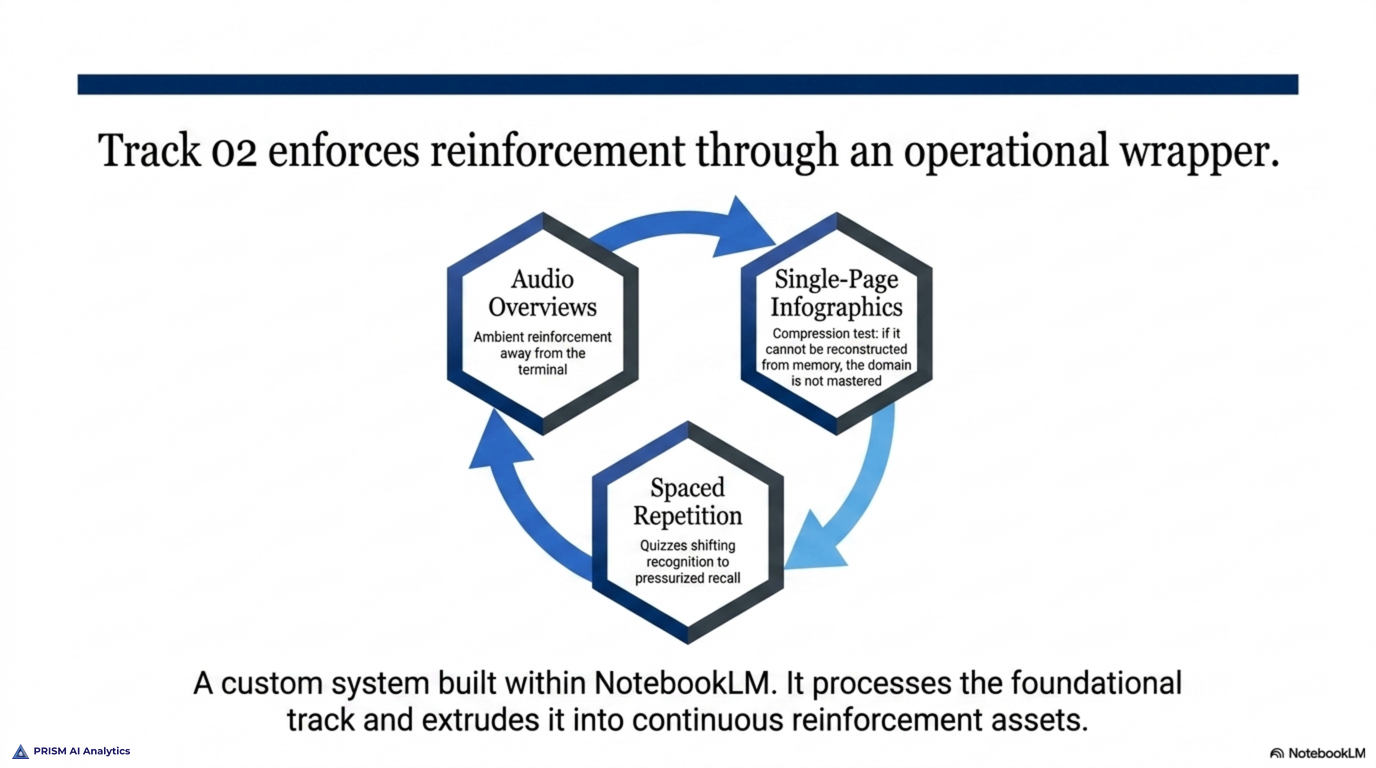
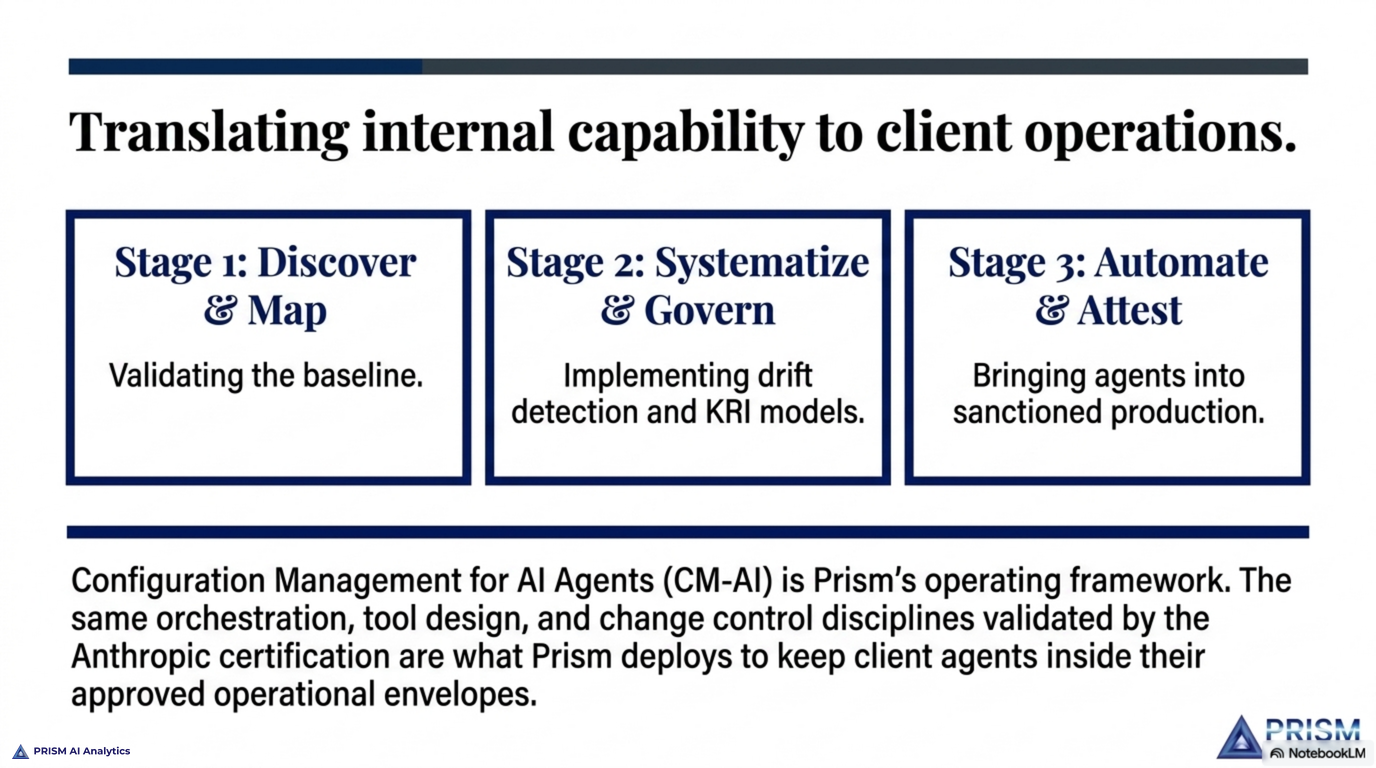
Neither track is the point on its own. The official curriculum teaches the material; the stack I built is how I drill it. The method is the combination — structured coverage on one side, self-assembled reinforcement on the other, both pointed at the domains the exam weights most heavily. It’s also, not coincidentally, a small version of how Prism approaches client work: use the official, documented capability as the foundation, then build the tooling around it that makes the capability dependable in practice.
The loop I keep noticing
I keep coming back to the auth-fix moment from that first morning, because it’s the whole series in miniature.
The barrier wasn’t conceptual. I understood the material fine. The barrier was operational — a piece of tooling that had quietly broken, standing between me and my own study materials. And the fix wasn’t to study harder or wait for someone to repair it. It was to treat the broken tooling as a small engineering problem, hand it to an agent, and clear it in twenty minutes so the actual work could start.
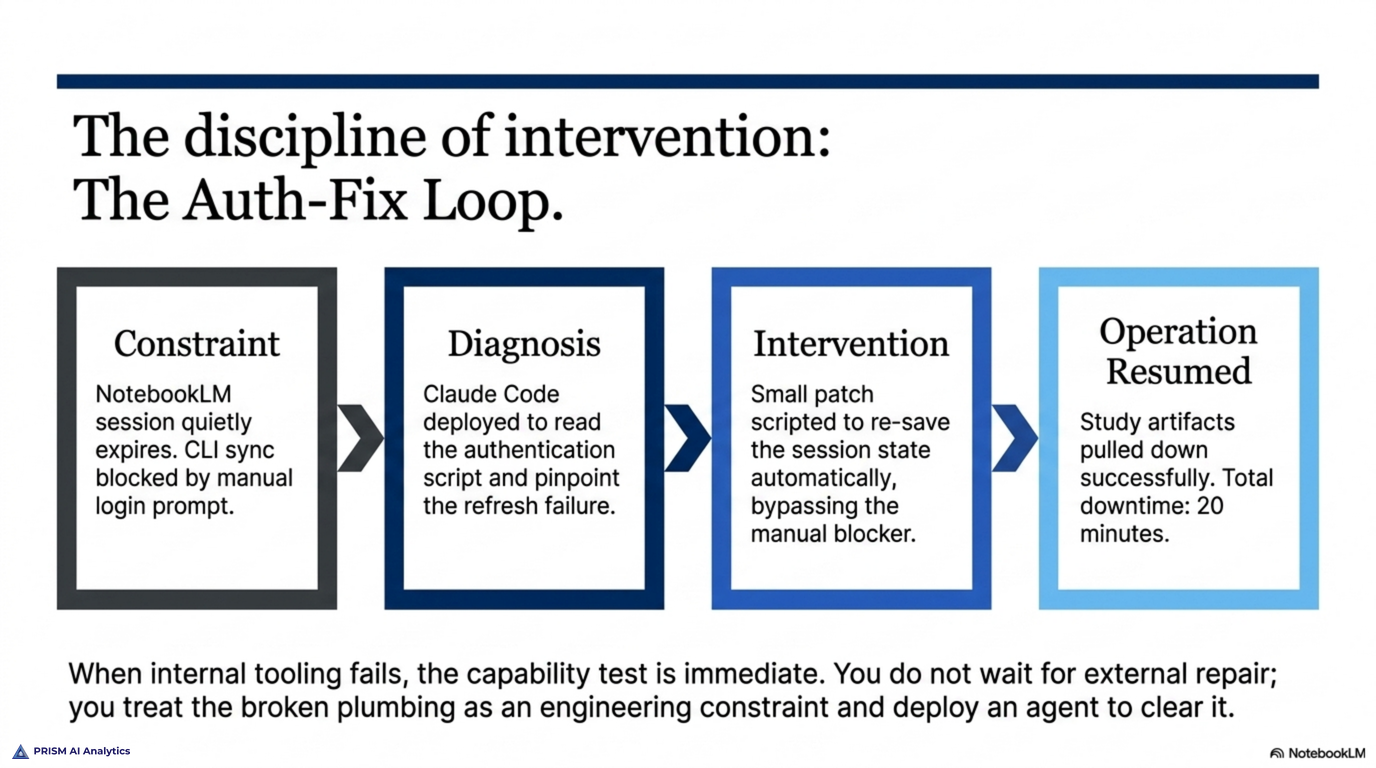
That’s the discipline the exam is testing, and it’s the discipline Prism sells: knowing the difference between a problem you reason your way through and a problem you build your way past — and being willing to stop, diagnose the plumbing, and fix it rather than working around it. I didn’t plan for my study setup to demonstrate the curriculum. It just did.

What I’ll share, and what I won’t pretend
A series written during preparation, before the outcome is known, only works if it’s honest. So the promise is method, not a victory lap. I’ll show what the study stack is good at and where it falls short, which domains came easily because Prism already lives in them and which ones exposed a gap, and what it’s like to be examined on tools you use daily versus the conceptual scaffolding underneath them.
The next post goes inside the study stack itself — how the NotebookLM artifacts get built, where they earn their place, and where they don’t. After that, the gap between operating the tools and being tested on them. And then, once I’ve sat it, the result — whatever it is.
Putting Agents to Work in Production?
Prism AI Analytics helps operators build the architecture and configuration management practices that keep autonomous agents inside their approved envelope — the orchestration, tool design, and change control that turn a capable agent into a dependable one.