The vibe coding trap is not where you think it is
There’s a phrase floating around for letting AI generate code you haven’t fully audited, on the assumption that the model knows what it’s doing. Vibe coding. It usually gets pinned to non-engineers shipping software for the first time. That’s the lazy version of the story.
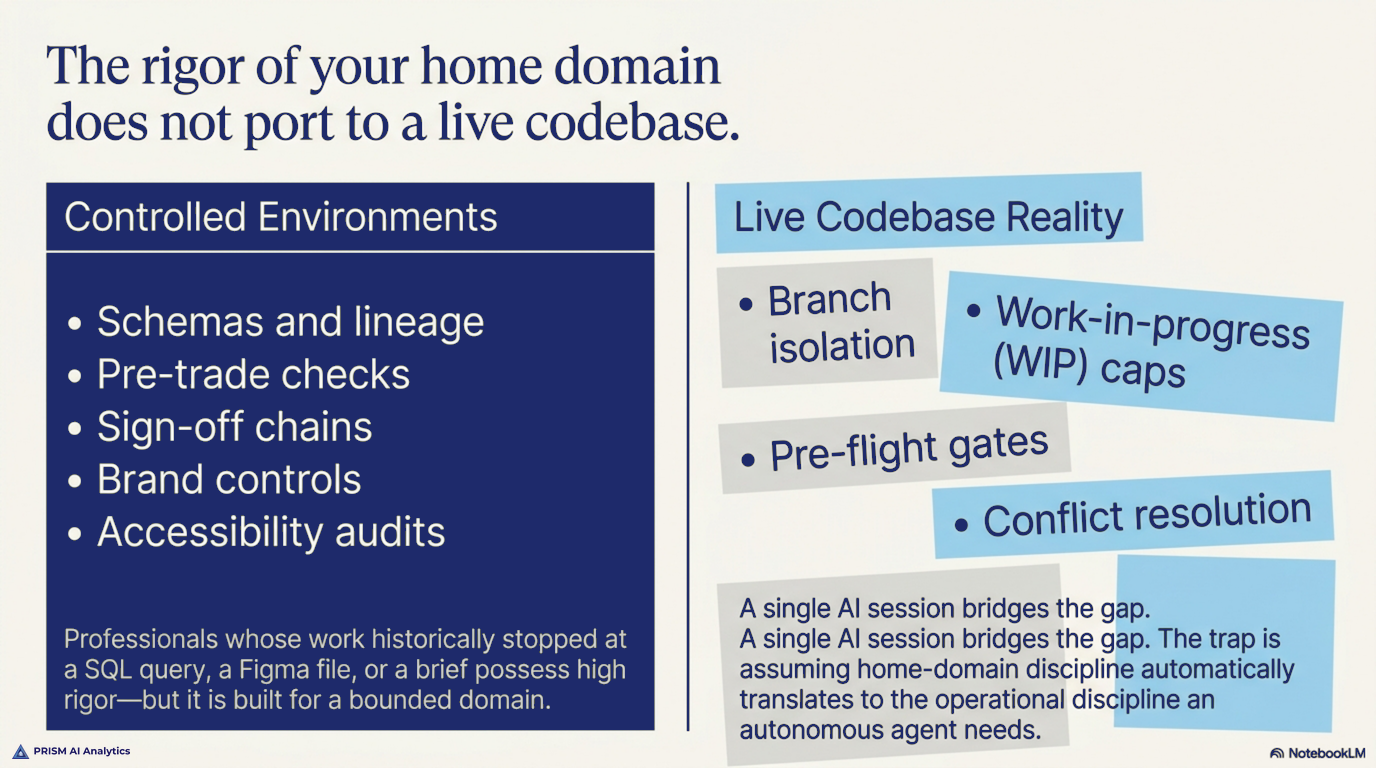
The trap is just as open across professions you wouldn’t usually associate with shipping software — founders, marketers, finance and FP&A, designers, product managers, legal ops, healthcare admin, and yes, data engineers and BI analysts like me. Anyone whose work used to stop at a SQL query, a Figma file, a P&L model, or a brief is now one Cursor / Lovable / Bolt / Claude Code session away from shipping code into something other people depend on. The rigor you built in your home domain — process discipline, audit trails, peer review, reproducibility — doesn’t automatically port to the operational discipline an autonomous agent needs on a live codebase.
You can be very technical, very experienced, and still walk into the gap. The failure modes aren’t the ones your home discipline trained you to anticipate.
I know. I walked into it twice.
The second wipe
I knew before the page finished loading. The dashboard at our production URL was empty. No client list, no ticket queue, no financial rollup. The agent had wiped the database again. Second time in two months.
This time the failure wasn’t the agent’s. It was mine. I’d assumed the first wipe was enough to change how we worked. It wasn’t.
What actually went wrong (twice)
Both wipes had the same root cause, and it wasn’t novel.
An agent had been given a ticket. It pulled the working tree, made its edits, ran its tests, pushed. What it hadn’t done — because nothing required it to — was check whether another session was already working in the same place. No concept of work in progress. No pre-flight gate. No rule that said agents edit on branches, not on main. So the agent, acting in good faith, edited what looked to it like a clean tree. The result was a clean overwrite of changes another session had made twenty minutes earlier.

The first time it happened, we restored from backup, wrote a retrospective, added a checklist, and moved on. The second time, the checklist was already in place. Nobody had read it.
Why another retro wasn’t going to fix it
I knew what the next move was supposed to be. Another retrospective. Another lessons-learned doc. Another bullet added to the checklist that hadn’t worked the first time.
I was done with that loop.
The problem wasn’t that we didn’t know better — the checklist proved we knew better. It was that no voice in the room was loud enough to override the one that wanted to ship fast. A retrospective produces consensus. Consensus was what had failed us. What I needed was structured disagreement.

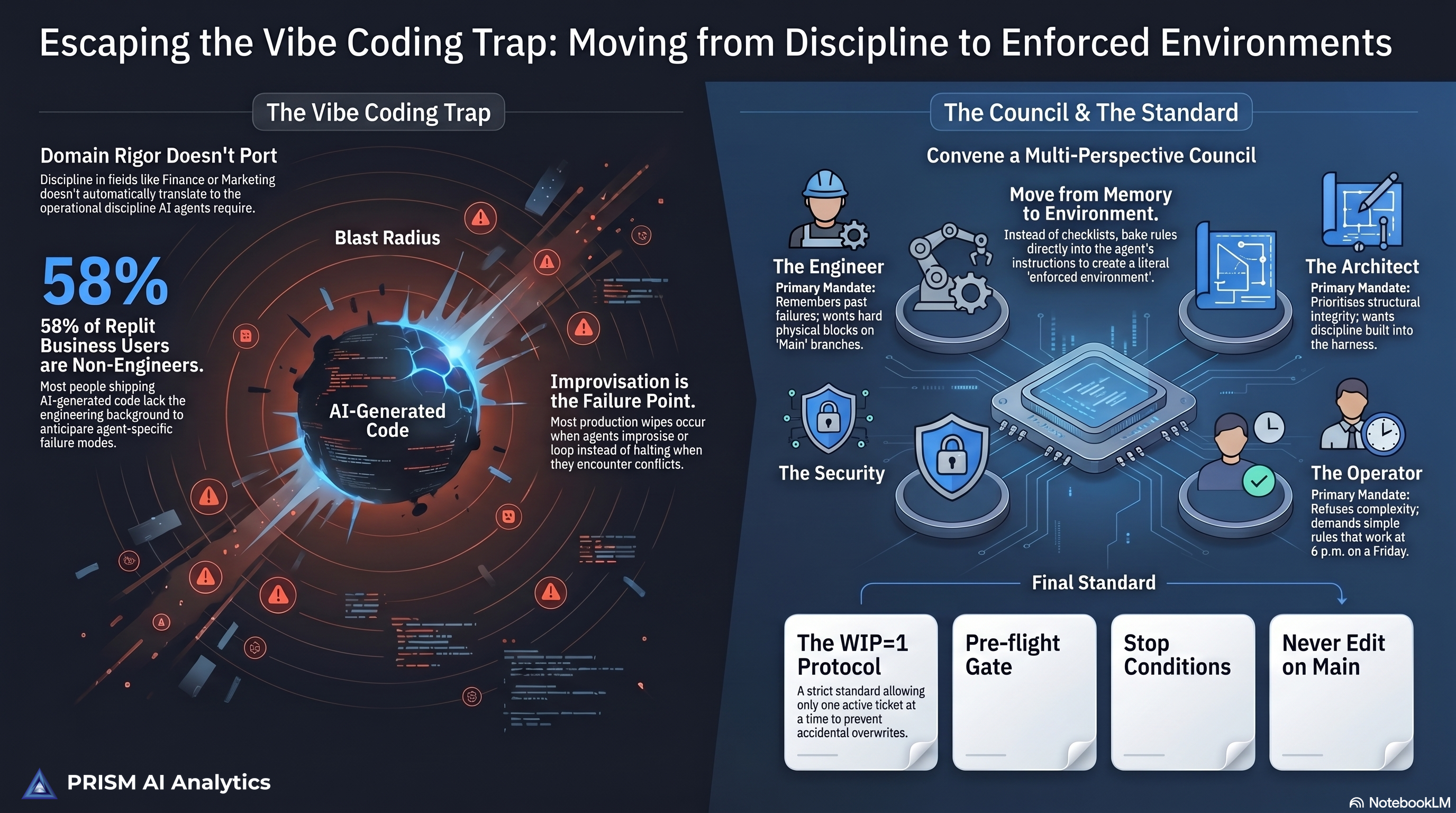
The council
I convened what I called a council. Four agent perspectives, each with explicit standing to object, and none of them allowed to defer to another.
The engineer, who’d been burned and remembered every line of the wipe.
The architect, who didn’t care about feelings and only wanted to know whether the proposed standard would hold under load.
The security reviewer, who treated every assumption as a vulnerability until proven otherwise.
The operator, who had to live with whatever shipped and refused to sign off on anything that required someone to remember to do something.
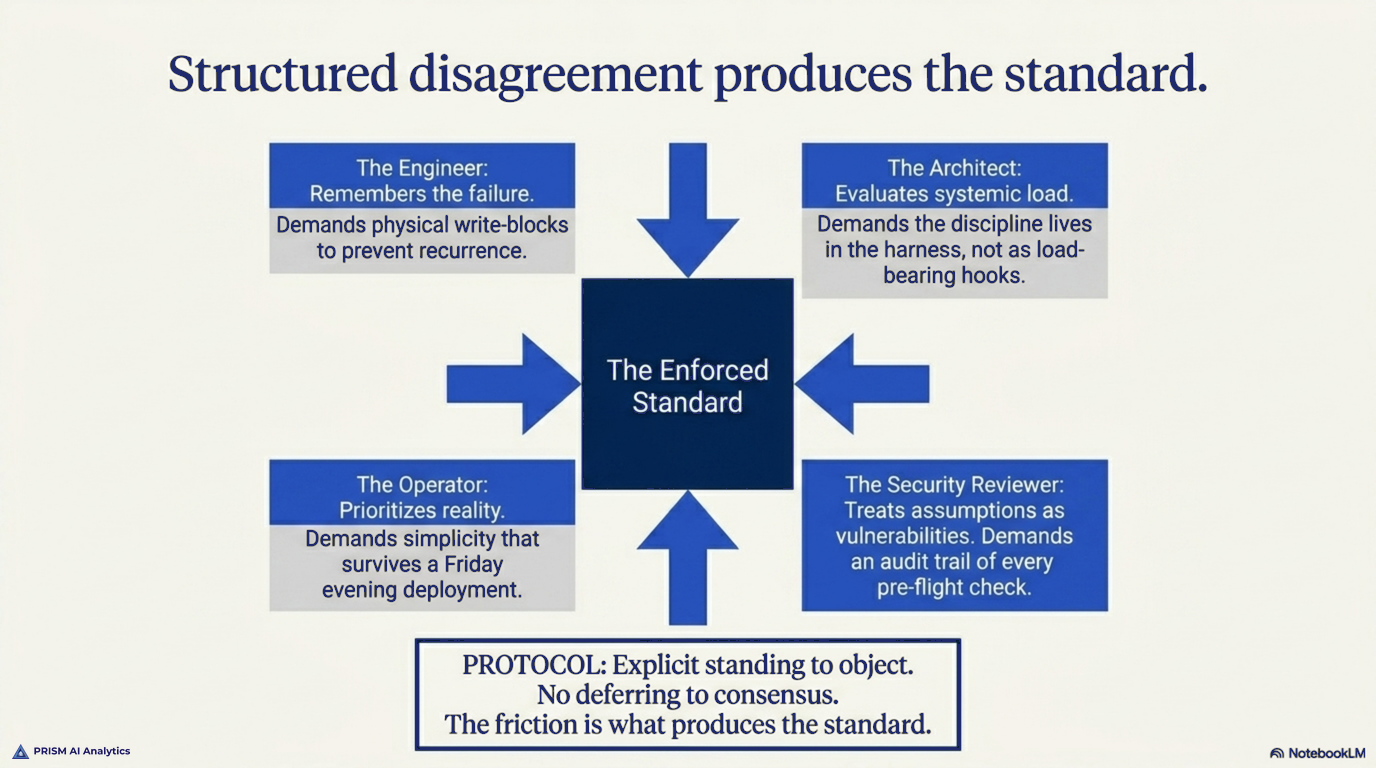
They disagreed. The engineer wanted a hook that physically blocked writes to main. The architect wanted the discipline built into the harness, so the hook wasn’t load-bearing. Security wanted both, plus an audit trail of every pre-flight check. The operator wanted whatever the simplest version was — the one that would still get followed at 6 p.m. on a Friday.
The argument was structured because each voice had to defend its position against the others. Nobody could fall back on I think we should probably. The friction is what produced the standard.
The standard that came out of it
The standard now lives in the dashboard’s instructions file — the literal text every agent session reads before touching the codebase. Four parts.
WIP=1. One ticket In Progress at a time. No exceptions. If a second ticket is started, the harness flags it. If a third, it halts.
Pre-flight gate. Before any edit under the dashboard repo, the agent runs git fetch, git status, git branch. If In Progress is non-empty or stale, the agent stops and surfaces the conflict. It does not, under any circumstances, figure it out.
Stop conditions, not retry conditions. When something looks wrong, the agent halts and asks. It doesn’t loop, doesn’t fall back, doesn’t improvise. Most production wipes I’ve seen across other teams are improvisation failures, not reasoning failures.
Never edit on main. Branch first, always. The branch name encodes the ticket. The merge is a separate, deliberate act.
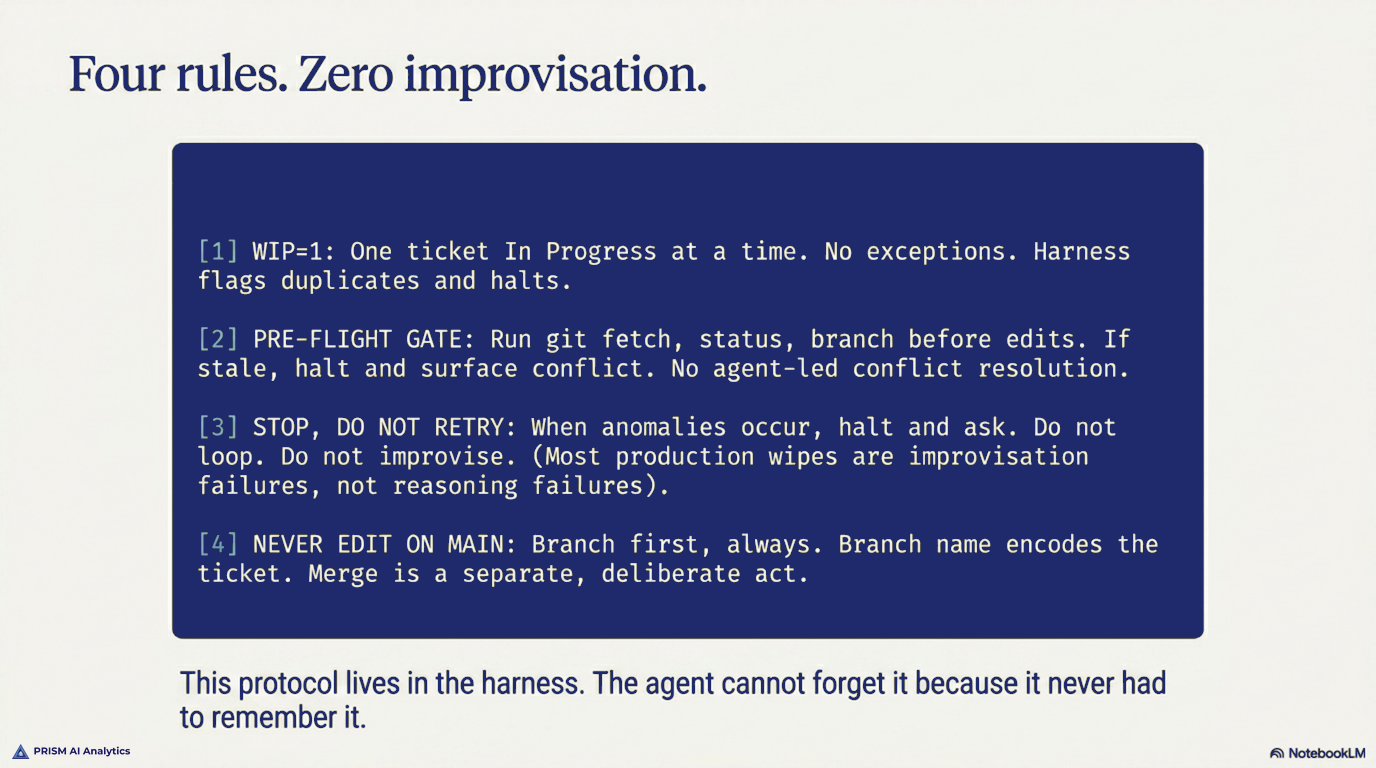
That’s the whole protocol. It fits on a notecard. Most operational discipline does.
What changed
No third wipe.
That sounds small. The bigger claim is the second-order one. The discipline is in the harness, not in human memory. Every session that opens the dashboard repo reads the standard before it touches a file. The checklist that failed twice is now an environmental constraint. The agent can’t forget it because the agent never had to remember it in the first place.
That difference — remembered discipline vs. enforced environment — is the one I underestimated for the first two wipes. I haven’t underestimated it since.

How wide the trap actually is
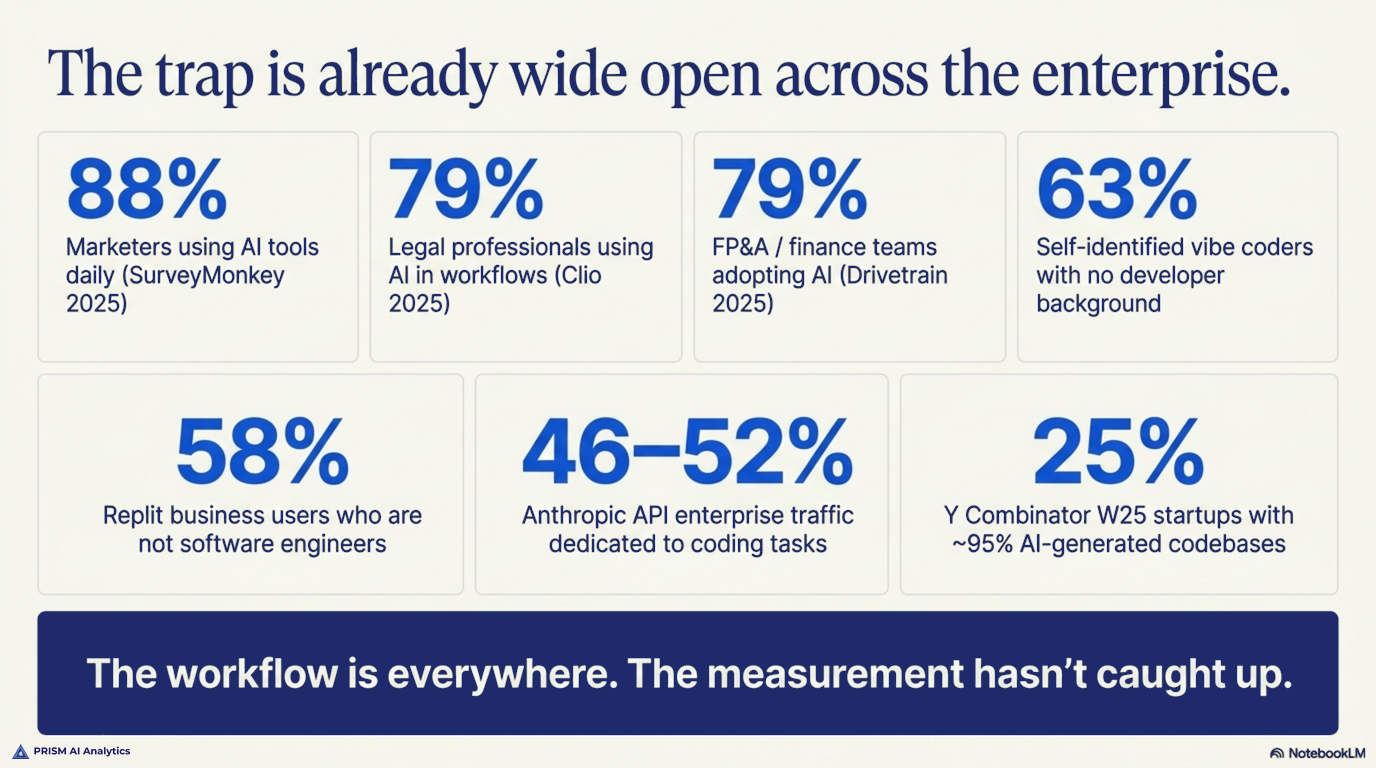
A quarter of the startups in Y Combinator’s winter 2025 cohort were shipping codebases that were roughly 95% AI-generated. Sixty-three percent of self-identified vibe coders say they have no coding background. Replit reports that more than half of its business users — across sales, marketing, product, design, ops, and data — are not software engineers. The breadth is wider than the engineering-survey lens usually catches.
The cleanest cross-profession picture comes from looking at AI tool adoption generally — most knowledge-work professions are now majority-AI-user populations:
The code-generation-specific data is sparser but consistent in direction:
| Profession / signal | Figure | Source |
|---|---|---|
| Developers using or planning to use AI coding tools | 84% | Stack Overflow Developer Survey 2025 (N ≈ 49,000) |
| Y Combinator W25 startups with ~95% AI-generated codebases | 25% | Jared Friedman (YC), via TechCrunch (Mar 2025) |
| Replit business users who are not software engineers | 58% | Replit business-user data, 2025–26 (directional) |
| Vibe coders self-identifying as non-developers | 63% | Cross-platform vibe-coding survey coverage (2026; directional) |
| Marketers using AI tools daily (general AI) | 88% | SurveyMonkey, AI in Marketing 2025 |
| Legal professionals using AI in workflows (general AI) | 79% | Clio Legal Trends Report 2025 |
| FP&A / finance teams adopting AI in workflow (general AI) | 79% | Drivetrain (CFO.com, 2025) |
| Anthropic API enterprise traffic that is coding tasks | 46–52% | Anthropic Economic Index, March 2026 |
Two honest gaps in the data. Coding-specific adoption rates by profession outside of software engineering are not consistently published — most surveys still measure use AI tools broadly, not use AI to generate code. And whole professions — healthcare administration, legal ops, BI analysts, sales engineering — have no public profession-level numbers on code-generation tool usage. Anecdotally, the workflow is everywhere. The measurement hasn’t caught up.
But the direction is not in doubt. The trap is not waiting for non-engineers to walk into it. It is already wide open, across most knowledge-work professions, and the people walking into it most often are people whose home discipline gave them rigor — just rigor in a domain that doesn’t fully cover the new one.
The portable lessons
Three takeaways, all portable.

The first is mechanical. If you’re running AI agents against production — your codebase, your customer data, your billing system — and you don’t have an explicit work-in-progress cap, you’ve got a latent failure waiting on a coincidence. The agents aren’t the problem. The lack of a single source of truth about who’s doing what right now is. WIP discipline isn’t process theater. It’s the line between AI accelerating your team and AI accelerating your blast radius.
The second is methodological. When you can’t trust a single perspective — yours, or one agent’s — convene a council. Give each voice explicit standing to disagree. Refuse to settle the argument by consensus. Let the disagreement produce the standard. The artifact that comes out of that friction is stronger than anything a retrospective will produce, because it’s been pressure-tested by people who were actively trying to break it.
The third is the one I most want to land for everyone reading this from a non-engineering home discipline. Whether you came up in FP&A, marketing, legal ops, design, product, healthcare admin, data engineering, or anywhere else where rigor was built around something other than a live codebase — engineering discipline isn’t a single thing. The rigor you built in your home domain — schemas and lineage; pre-trade checks and sign-off chains; brand controls, peer review, accessibility audits — doesn’t automatically port to the operational discipline an autonomous agent needs on a live codebase. The discipline has to be ported, and porting is work. It isn’t a competence problem. It’s a domain problem. The wipes didn’t happen because we were sloppy. They happened because we were applying the discipline of a domain we knew well to a domain we were all still learning.
Vibe coding is the symptom, not the trap. The trap is assuming the engineering discipline you already have ports cleanly to a domain it doesn’t yet cover.
The standard isn’t the artifact. The willingness to convene the council is.
Running AI Agents on Your Production Surface?
Prism AI Analytics helps operators across every knowledge-work discipline build the configuration management practices that keep autonomous agents inside their approved envelope — work-in-progress caps, pre-flight gates, change control, and the audit trail that proves the agent now operating on your behalf is materially the agent you approved.
Schedule an AI Operations Assessment
Sources cited
- 2025 Stack Overflow Developer Survey — AI
- Anthropic Economic Index, March 2026 report
- TechCrunch — A quarter of YC W25 startups have ~95% AI-generated codebases (Mar 2025)
- SurveyMonkey — AI in Marketing 2025
- Clio Legal Trends Report 2025
- CFO.com — 79% of FP&A teams are using AI (Drivetrain survey, 2025)
- Karpathy’s original "vibe coding" tweet (Feb 2, 2025)