When we launched Prism AI Analytics two months ago, the conviction was simple: Claude would be foundational to how we work. The execution was not. For the first three weeks, every session started the same way — pasting context, restating goals, repeating decisions that had already been made the day before. Claude was on the team in the way a senior consultant is on the team when nobody schedules a meeting with them. Present, capable, almost entirely unused.
The fix was not better prompting. It was a system.
This post is the operational record of that system — the actual configuration, agents, rules, and rituals Prism uses to run a multi-workstream consulting firm with Claude wired into every layer of the work. It is written for solopreneurs and small-team founders who have the same conviction and the same gap. The names are real. The systems are real. The order in which we built them matters more than any individual piece.
The problem nobody warns you about
The dominant narrative about Claude adoption is a prompting story. Write better prompts and you will get better output. That is technically true and operationally useless. The bottleneck for a working business is not prompt quality — it is the sheer cost of reconstructing context every time you open a new chat.
Three weeks in, we ran the numbers on a normal workday. Roughly forty percent of every Claude session was spent re-explaining: who we are, what we are working on, what was decided yesterday, where to find the relevant files, which workstreams are active, who the client is, what the brand voice rules are, what we have already tried and ruled out. The actual work — the part where Claude does something we could not have done as fast alone — was a thin slice on top of a thick base of repetition.
That is not a model problem. That is a system problem. The model has no memory of what happened last session. If we want continuity, we have to engineer it. If we want consistency, we have to specify it. If we want speed, we have to remove the friction we are introducing ourselves every time we open a fresh window.
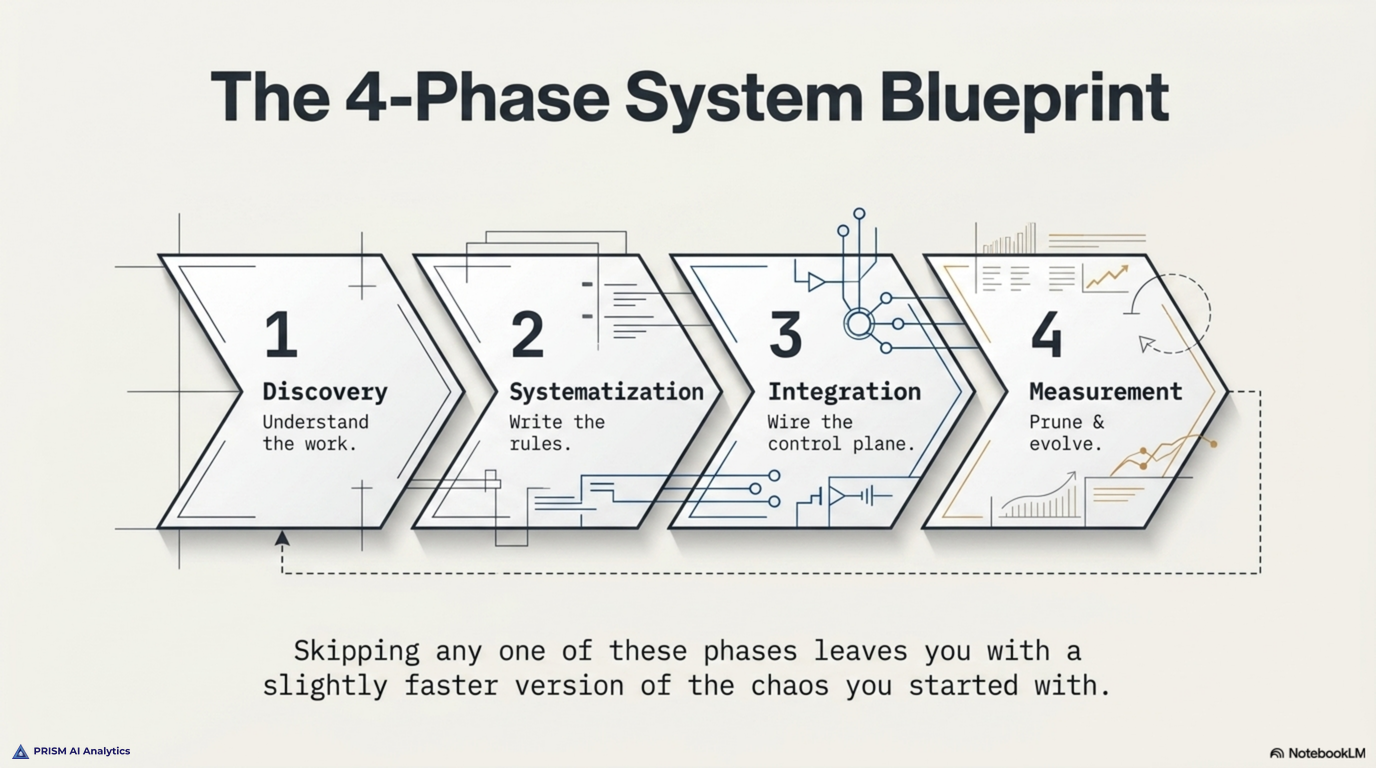
This is the gap the four-phase build closes. Discovery first — understand the actual work. Then systematization — write down the rules the work runs on. Then integration — wire the rules into a control plane the agent can read at session start. Then measurement — track what is actually working and prune what is not. None of these phases is optional. Skipping any one of them leaves you with a slightly faster version of the chaos you started with.
Phase 1 — Discovery and Mapping
The first step in building a Claude operating system is not learning Claude. It is learning your own firm.
Prism runs ten declared workstreams: Client Work, Marketing, CRM Development, Content, Admin, Training, AI Bridge, Sales & Outreach, Finance, and a generative product surface we call Prism Studio. Each one has its own cadence, its own artifacts, its own audience, its own definition of done. The first thing we did — before writing a single agent specification, before configuring memory, before building a single tool — was sit down and inventory every recurring task in every workstream and answer two questions about each one.
The first question was, is this work where the bottleneck is judgment, or where the bottleneck is throughput? Judgment-bottlenecked work — deciding pricing for a new engagement, picking which of three competitive directions to take a client — stays human. Throughput-bottlenecked work — drafting outreach sequences, normalizing data, producing standard-format briefs — is exactly where Claude earns its keep.
The second question was, what context does this task actually need? Most tasks need far more than a fresh chat ever has access to. A client status update needs the engagement history. A pricing decision needs the firm’s positioning. A blog draft needs the brand voice rules. A handoff doc needs the prior session’s decisions. Tasks that get the right context produce useful output. Tasks that do not, produce confident-sounding generic copy that is worse than nothing because it has to be unwound before it can be replaced.
The mapping exercise took roughly six hours over two days. The output was a single spreadsheet of every recurring task across all ten workstreams, sorted by Claude zone (Claude takes the first draft, human reviews) versus Claude assist (human drafts, Claude critiques or expands) versus human only (judgment, sensitive client communication, anything where the cost of a wrong call exceeds the cost of a slow call). That spreadsheet became the source of truth for everything we built after it. Without it, every subsequent decision would have been guesswork.

If you do nothing else from this post, do the mapping exercise. Six hours. Two columns. Claude zone, human zone. The system you build on top will be exactly as good as that spreadsheet.
Building a Claude operating system for your team? Start a conversation about what you’re optimizing for. The mapping exercise alone changes how a firm spends its hours.
Phase 2 — Systematization
Once we knew where Claude belonged, we wrote down the rules of engagement. Not prompts — rules. The distinction matters.
A prompt is a one-time instruction in a single chat. A rule is a persistent specification that every session inherits. Prism’s rules of engagement live in a file called CLAUDE.md at the root of every project directory. When a new session starts, Claude reads it before doing anything else. The file is around 400 lines today. It specifies which projects live where, which directories are content versus build artifacts, how the firm thinks about tickets (the unit of work is a ticket, never a task), how handoffs are structured, what the deployment surfaces are, and which platform conventions apply (Windows shell, PowerShell syntax, no /dev/null).

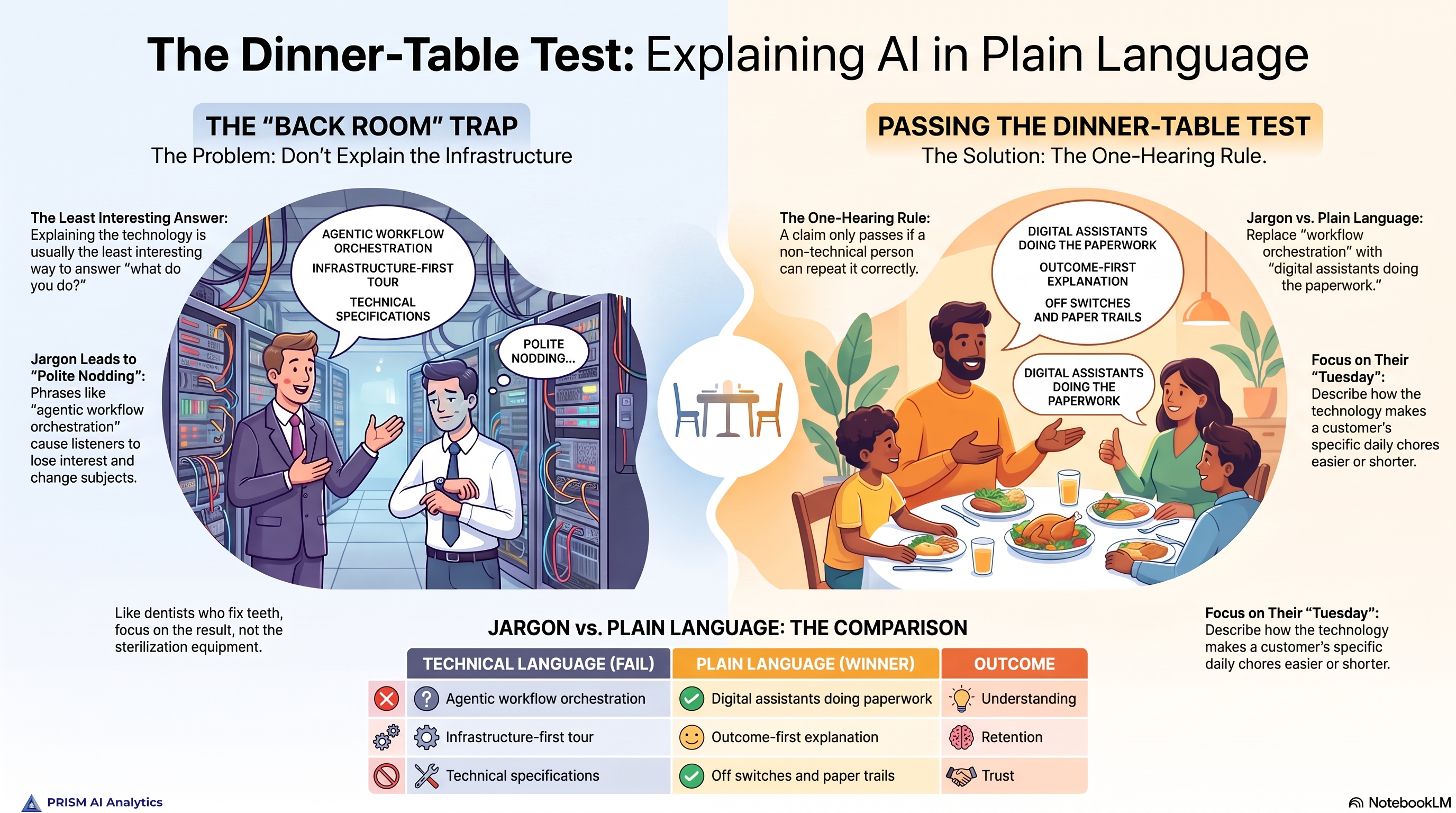
The brand has its own rules file: prism-marketing/brand/do-not-do.md. Every piece of public content gets swept against it before it ships. No exclamation points. No third-party statistics in the opening of a post. No fake intimacy. No fusing the Prism brand with any single framework or product. The file is opinionated on purpose. Calm expert in a noisy room is the voice; anything that breaks that voice gets rewritten or cut.
Beyond the rule files, we specialized. Prism does not run one general-purpose Claude. It runs nine domain agents, each scoped to a workstream: chief-of-staff, finance-billing-ops, client-delivery-ops, sales-bd-ops, marketing-ops, research-analytics-ops, internal-admin-ops, and a few others. Each agent has its own system prompt, its own preferred tools, its own escalation rules. When work belongs to a domain, we route it to the domain agent, not the generalist. The marketing agent already knows the brand rules, the active campaigns, and the channel calendar. Asking the generalist to take a marketing task means re-teaching it everything the marketing agent already knows.
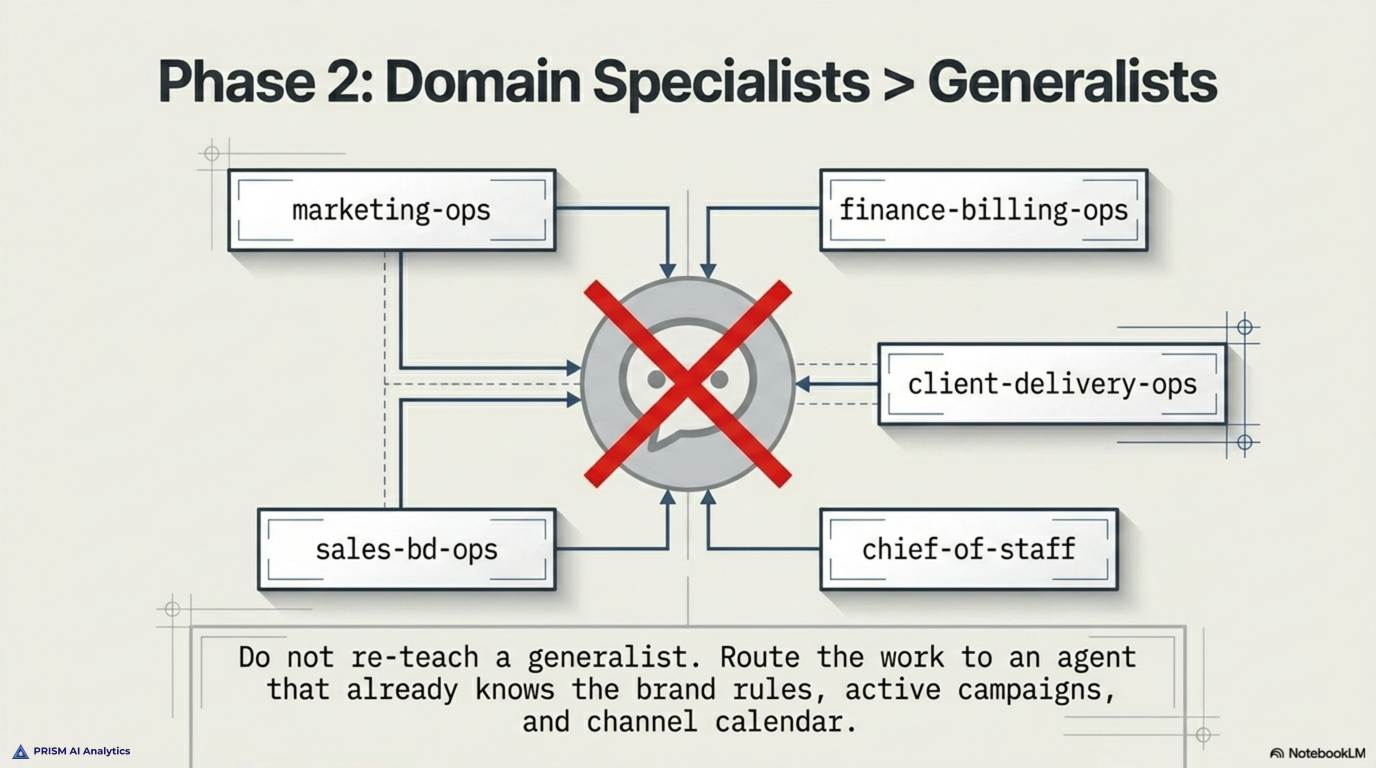
The two-hour investment in writing the rules files paid back inside the first week. Output that used to require three turns of correction comes out usable on the first turn. Sessions that used to open with a paragraph of context-setting now open with the actual question. Multiply that across a working week and the time recovered is not a marginal gain — it is the difference between Claude being a hobby and Claude being staff.
Phase 3 — Integration
Systematization tells Claude what good looks like. Integration is the harder problem: making Claude part of the work itself, not an optional sidecar.
Prism’s integration layer has three pieces, each of which earns its name.
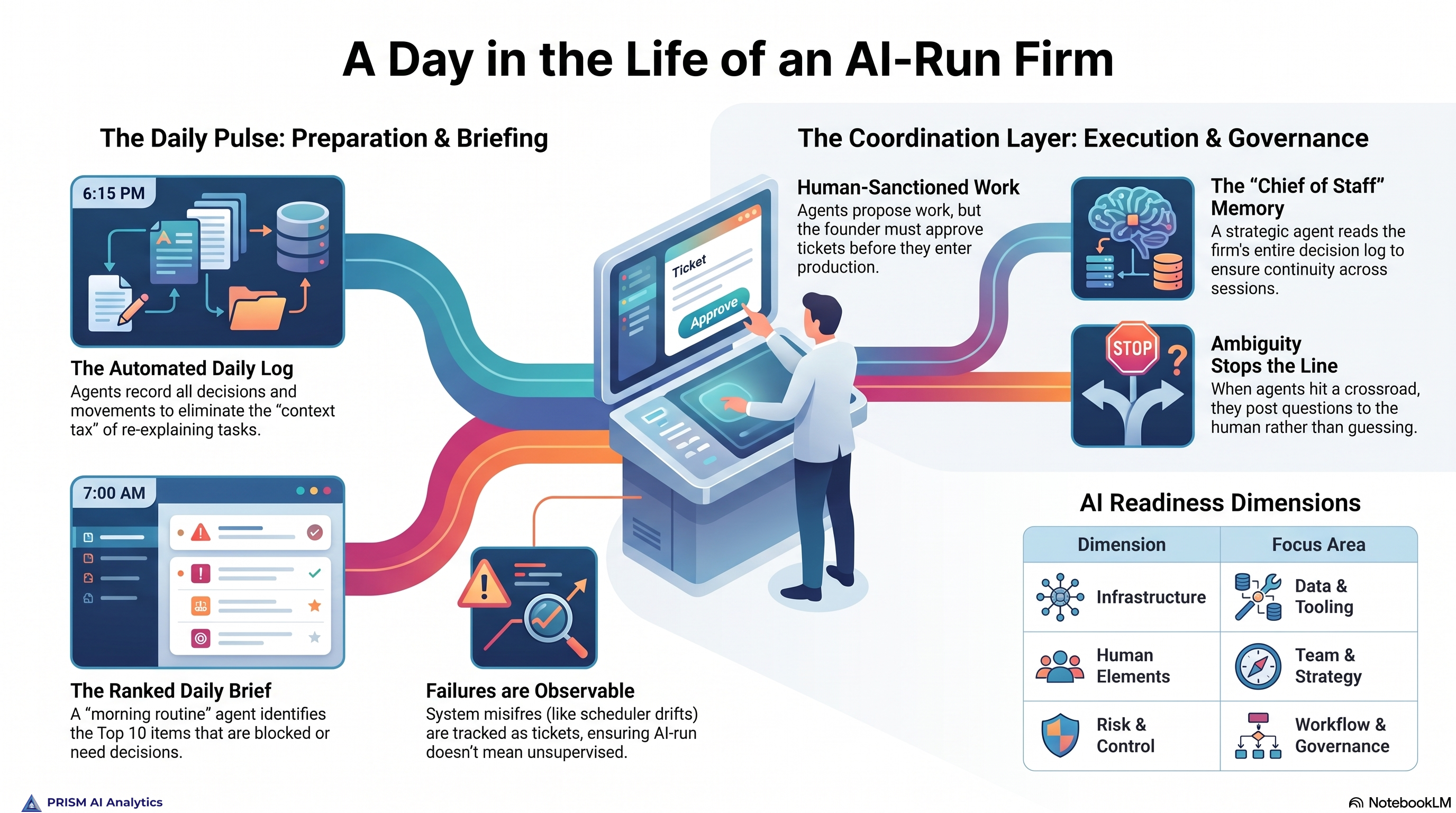
The first is Chloe, the firm’s strategic Chief of Staff. Chloe is not the operational chief-of-staff agent that dispatches tickets. Chloe sits one level above that — the thinking partner across all workstreams, the dot-connector, the voice that surfaces what is in flight before suggesting what is possible. Chloe auto-loads at the start of every Claude session. She reads the working hypotheses file, the open questions log, the last seven days of decisions, the last thirty days of Daily Logs, and the active project decision files. By the time the first human message is processed, Chloe knows the state of the firm. The opening line of every session reflects that — the Inbox count, the number of tickets awaiting a decision, the active critical path. No more pasting context. The context is already there.
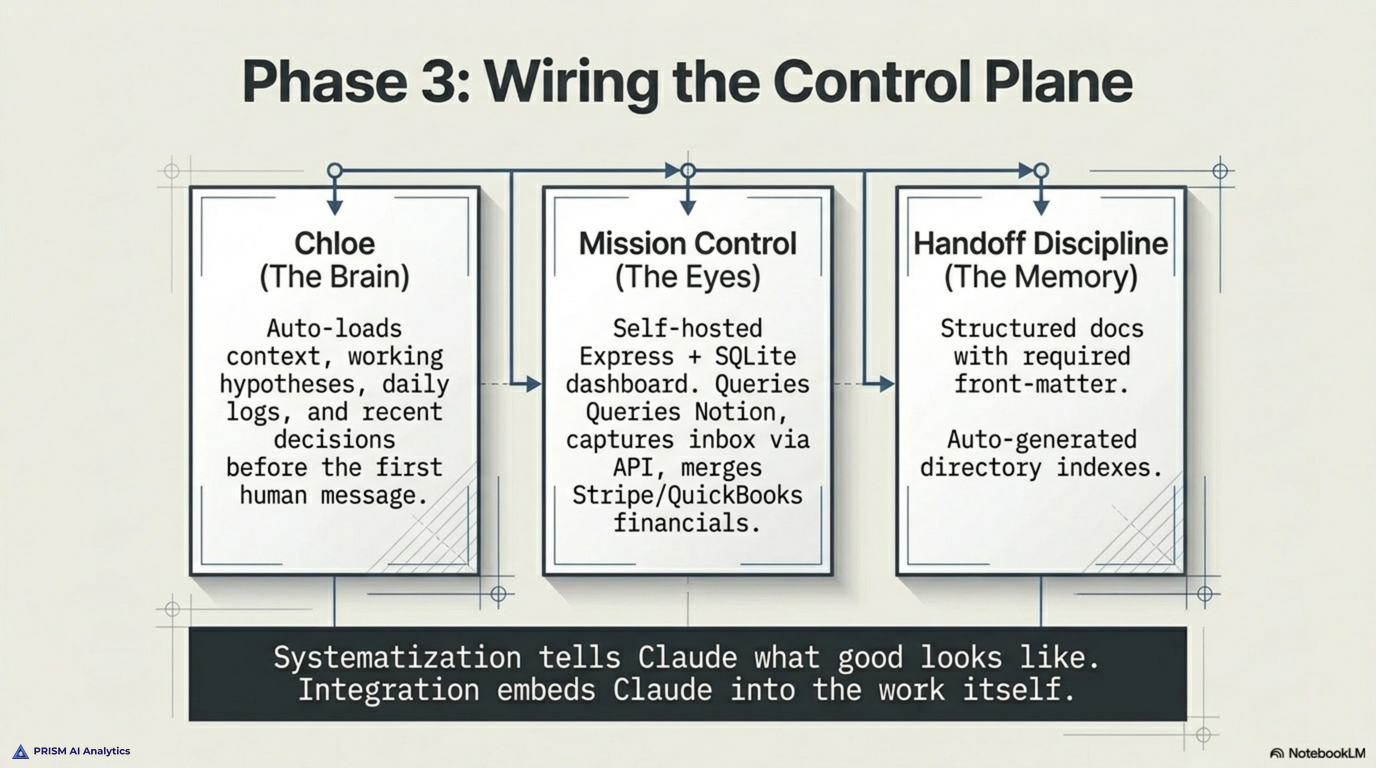
The second is the Mission Control dashboard, a self-hosted Express + SQLite application running at a Railway URL. The dashboard is the firm’s control plane. It exposes the Notion Tickets database as a queryable surface, surfaces tickets that need a decision, tracks daily reviews, captures Inbox items via a POST /api/mission-control/inbox endpoint that Chloe can write to mid-session, and merges financial state from Stripe and QuickBooks into a single financials view. The dashboard is not a vanity display. It is the operating surface the human owner uses to steer the agents, and it is the audit trail that proves what got decided when.
The third is the Handoff discipline. Every multi-session piece of work gets a structured handoff doc with required front-matter: status, created date, last-updated date, ticket ID, owner, and a supersedes pointer if it replaces a prior handoff. Handoffs live in a single canonical directory, never duplicated, never renamed with version suffixes. An index file is auto-generated from a script that scans the directory, parses the front-matter, and writes the active handoffs in last-updated order. Any future session — human or agent — can answer what is the latest version? deterministically.
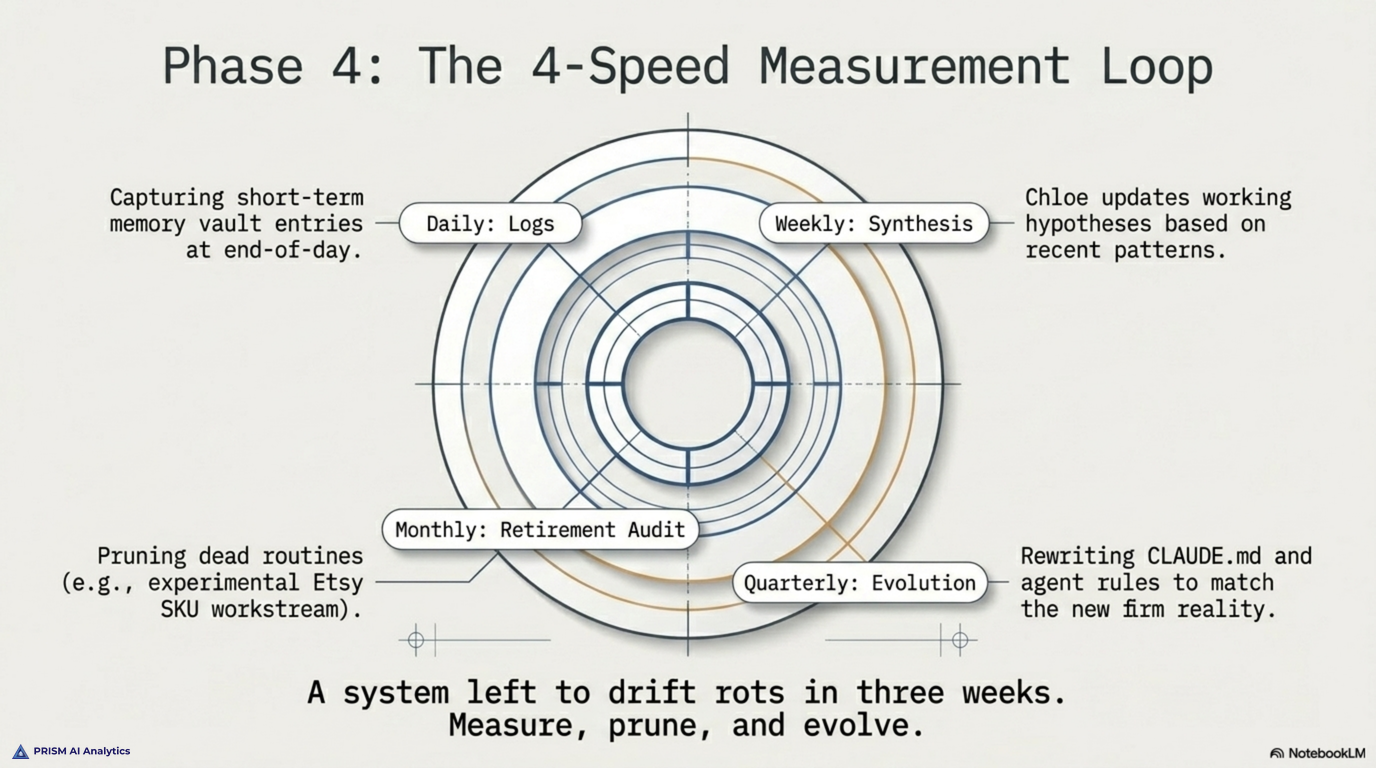
Tying these three pieces together is the ticket workflow. The unit of work at Prism is a ticket in Notion, not a task. Tickets flow through six states: Backlog (proposal), To Do (sanctioned), In Progress (active), Review (agent needs a decision), Blocked (waiting on external input), and Done. When an agent mid-session needs a judgment call, it posts the question to the ticket’s comments with the literal token [NEEDS-DECISION] in the body. The dashboard auto-flips the ticket to Review in the same request. The Mission Control daily tile increments. The owner sees the question on her next dashboard refresh, replies via a Reply & Resume composer, and the ticket flips back to In Progress. The agent does not block silently. The owner does not get interrupted in the middle of unrelated work. The state of every open question is, at all times, visible from one screen.
Integration of this depth takes longer than systematization. The dashboard alone is several thousand lines of single-file Express code, an Excel importer, a Stripe webhook, a QuickBooks OAuth flow, and a scheduled job that synchronizes Daily Log entries to the production database every evening. We did not build it in a weekend. We built it iteratively over six weeks, in tickets, deployed continuously, with each piece replacing a workflow that had been done in spreadsheets and chat messages the week before. The discipline that kept the build tractable was the same discipline we were building for — tickets, handoffs, Chloe synthesizing weekly hypotheses about what was working and what was not.
Phase 4 — Measure and Iterate
A Claude operating system is not a static configuration. It is a living thing that has to be measured, pruned, and evolved or it rots faster than any other internal tool a firm owns.

Prism’s measurement layer has four pieces, each operating on a different timescale.
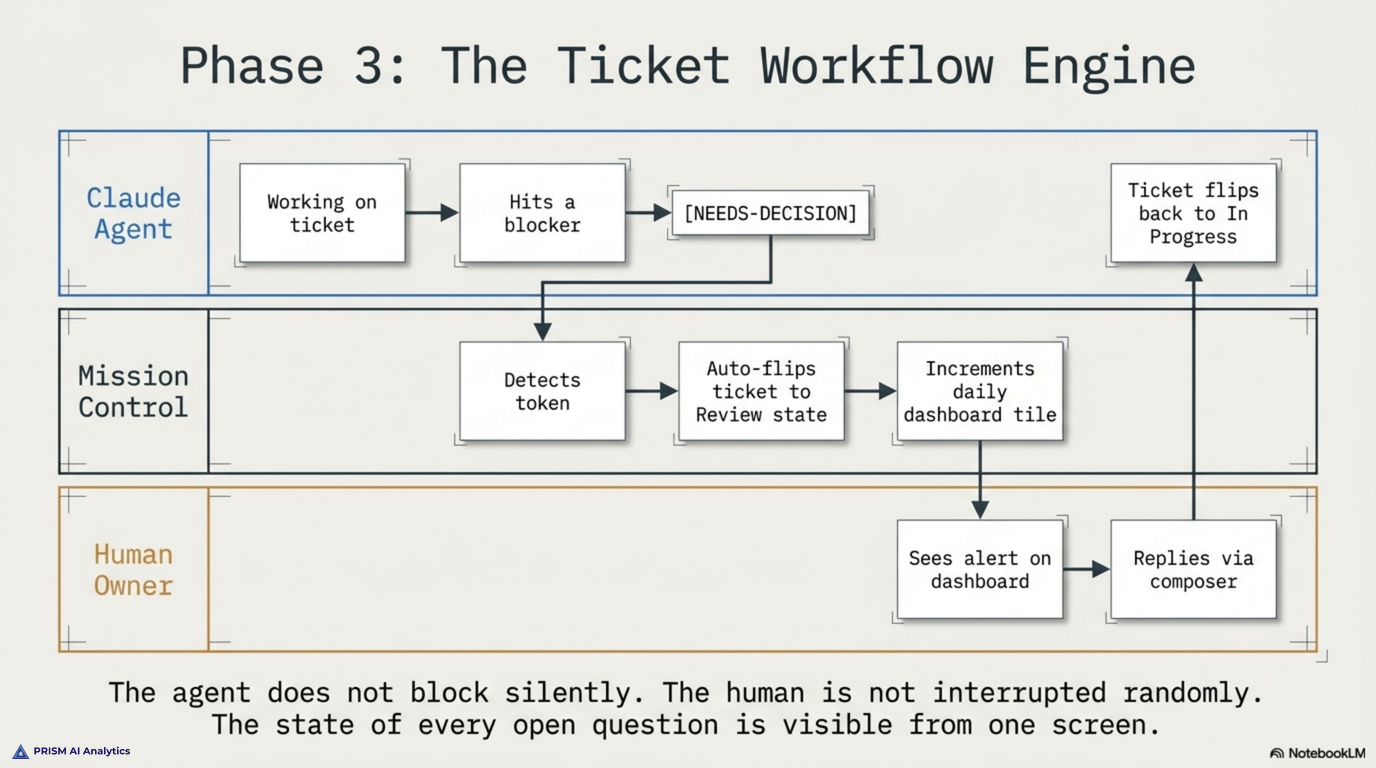
Daily Logs capture what got done in a working day — tickets moved, decisions made, blockers hit. They live in a vault directory and are written at end-of-day. The dashboard surfaces a Daily Review form that POSTs to the production database; a scheduled routine syncs the local Daily Logs to the production endpoint every evening at six o’clock. The logs are the firm’s short-term memory.
The weekly synthesis is Chloe’s job. On the first Claude session of every week, Chloe reads the last seven days of Daily Logs, the last seven days of the decisions log, and the current state of open questions, and updates the working-hypotheses file with any new patterns observed. Superseded hypotheses are marked explicitly, not deleted — the record of what we used to believe is itself valuable. If a full week passes with zero Claude sessions, the synthesis carries to the next week’s first session.
The monthly retirement audit is the harshest discipline of the four. Once a month, we look at every recurring routine, every scheduled agent, every active workstream, and ask: is this still earning its keep? In the past six weeks we have retired four prism-studio skills (the experimental Etsy SKU workstream did not generate signal proportional to its operational cost) and the dev-insights-sync orchestrator step (auto-ticket flow needed redesign before re-enabling). Each retirement is a memory entry, not a deletion — if the assumption underneath the retirement turns out to be wrong, we want to be able to find what we knew when we made the call.
The quarterly evolution is where the rules files themselves get rewritten. CLAUDE.md gets new sections; the brand voice rules get tightened; agent specifications get refactored against what the past quarter actually produced. The rules are the contract; the contract evolves with the firm.
The crude headline metric, after the build settled, is that we recover something on the order of eight to ten hours per week of operational time compared to the manual baseline of the first three weeks. That number is a lower bound; the more honest version is that several categories of work — ticket triage, daily log synthesis, brand-voice sweeps, handoff index generation, multi-source research — are simply done now, where in week one they were not done at all. The recovered time is not the point. The recovered headspace is.

Honest caveats
This is not a finished system. It is the snapshot of an iterating one.
Three things are still rough. First, the orchestrator step that auto-creates tickets from session activity is currently disabled — the heuristics produced too many duplicate tickets in May and we pulled the plug while we redesigned. Second, the dashboard’s financials view merges Stripe and QuickBooks data correctly for revenue but still does some manual reconciliation for cash flow that we have not yet automated. Third, the Mission Control dashboard depends on a Railway-hosted backend that has a single point of failure in the SQLite write path; production has been wiped twice in the past quarter from operator error and we now run a strict WIP-of-one protocol on the dashboard’s main branch to prevent recurrence.
The system is also expensive in attention. The rules files, the dashboard, the handoffs, the agents, the weekly synthesis — none of these maintain themselves. The firm spends real hours every week curating the operating system itself. That cost is offset by the hours recovered downstream, but only as long as the curation is done. A Claude operating system that is left to drift is, after about three weeks, indistinguishable from the chaos it was built to replace.
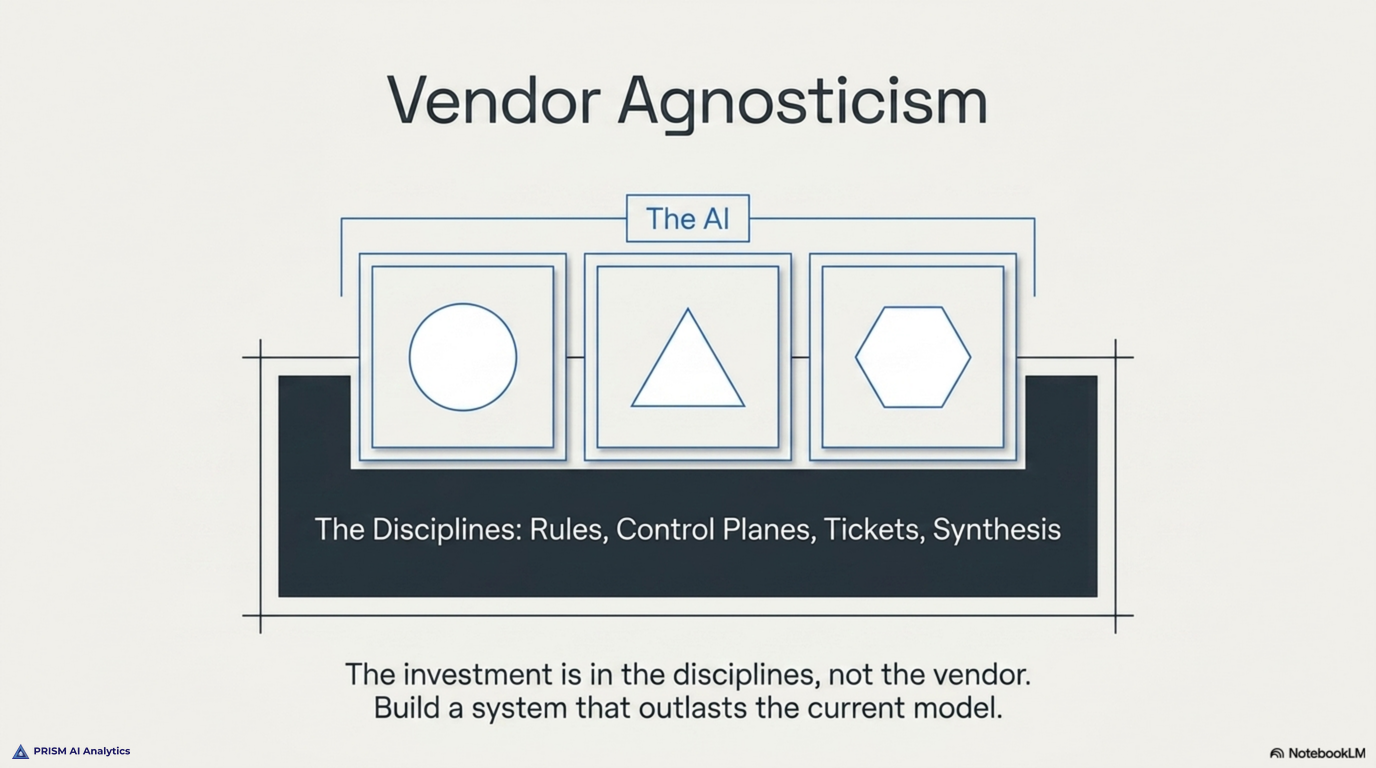
And there is a tooling caveat. Everything described above runs on Claude Code and the Claude API, plus the wider Anthropic stack of skills, agents, and MCP connectors. The same disciplines — rules files, a control plane, a ticket workflow, a synthesizer that runs at session boundaries — will work with other agentic platforms. The investment is in the disciplines, not in any single vendor. Choose your platform deliberately; we chose ours because of the depth of the Agent SDK and the maturity of the MCP toolchain, not because we believe the platform is permanent.
Where to start if you are reading this with conviction and no system
You do not need ten workstreams. You do not need a dashboard. You do not need nine specialized agents. You need three honest answers.
What is the actual work you do every week? Write it down. Not the work you wish you did, the work you actually do.
Where are you repeating yourself when you talk to Claude? Every repetition is a candidate for a rules file. Write the rules down once. Read them every session.
What decisions, in your week, did you make twice because you forgot you had already made them? That is the case for a decisions log, even if it is one markdown file in a folder somewhere.

Start with one task. Write the rules. Read them at session start. Iterate. By the end of the second week you will know whether the discipline is taking hold. By the end of the second month you will have an operating system.
The conviction that Claude can be foundational to how a firm runs is correct. The system to make that conviction real does not show up by itself. Build it deliberately. The compounding is real.

\*Prism AI Analytics helps solopreneurs and small teams design and ship Claude operating systems. If you have the conviction and want a partner on the build, start a conversation.\*
Ready to Build Your Own Claude Operating System?
Prism AI Analytics designs and implements Claude integration systems for solopreneurs and small teams. We bring the disciplines — rules, control planes, ticket workflows, weekly synthesis — that turn ad hoc AI use into compounding firm capacity.