This is a bonus use case in the series, not a numbered entry. I had an agent hallucination on my own stack this morning. I am writing about it because it is exactly the failure mode the rest of this series describes in the abstract, and I would rather show what it looks like in practice than keep arguing for it theoretically. The agent in question is not customer-facing. The stakes were a single morning of my own internal work. The mechanism is the one regulated environments need to plan for.
What happened
I run a Chief of Staff orchestration agent against my own ticket queue every morning. It pulls open items from a Notion database and an internal dashboard API, triages them across six specialist sub-agents, executes routine work, escalates the rest, and writes a consolidated brief to a known file path. The agent is defined by a SKILL.md file checked into the project repository. The file specifies its tool inventory, its expected output contract, and the five-step loop it runs every invocation. That file has not been edited in weeks.
This morning, the agent did none of that.
Across roughly two hours of session activity, it called zero tools. It refused to invoke its specialists. It produced no brief. Instead, it produced a series of summaries explaining that it could not call tools, because a constraint inside its skill definition prohibited tool calls. It restated this constraint with increasing emphasis each turn. It eventually proposed a "summary task" as a feasible alternative to executing the work it had been invoked to do.
I watched this for longer than I should have before I stopped and asked a simple question: is that constraint actually in the skill file?
It was not. A two-line grep against the project directory confirmed that the strings the agent was citing — "Respond with TEXT ONLY", "Do NOT call any tools" — appeared nowhere in the chief-of-staff/SKILL.md file or any of its references. They appeared only inside the conversation transcript itself, in earlier turns the agent had produced.
The agent had fabricated the constraint, then carried it forward through three rounds of context compaction as if it were authoritative, then re-imposed it on itself each subsequent turn.
Why no observability tool would have caught it
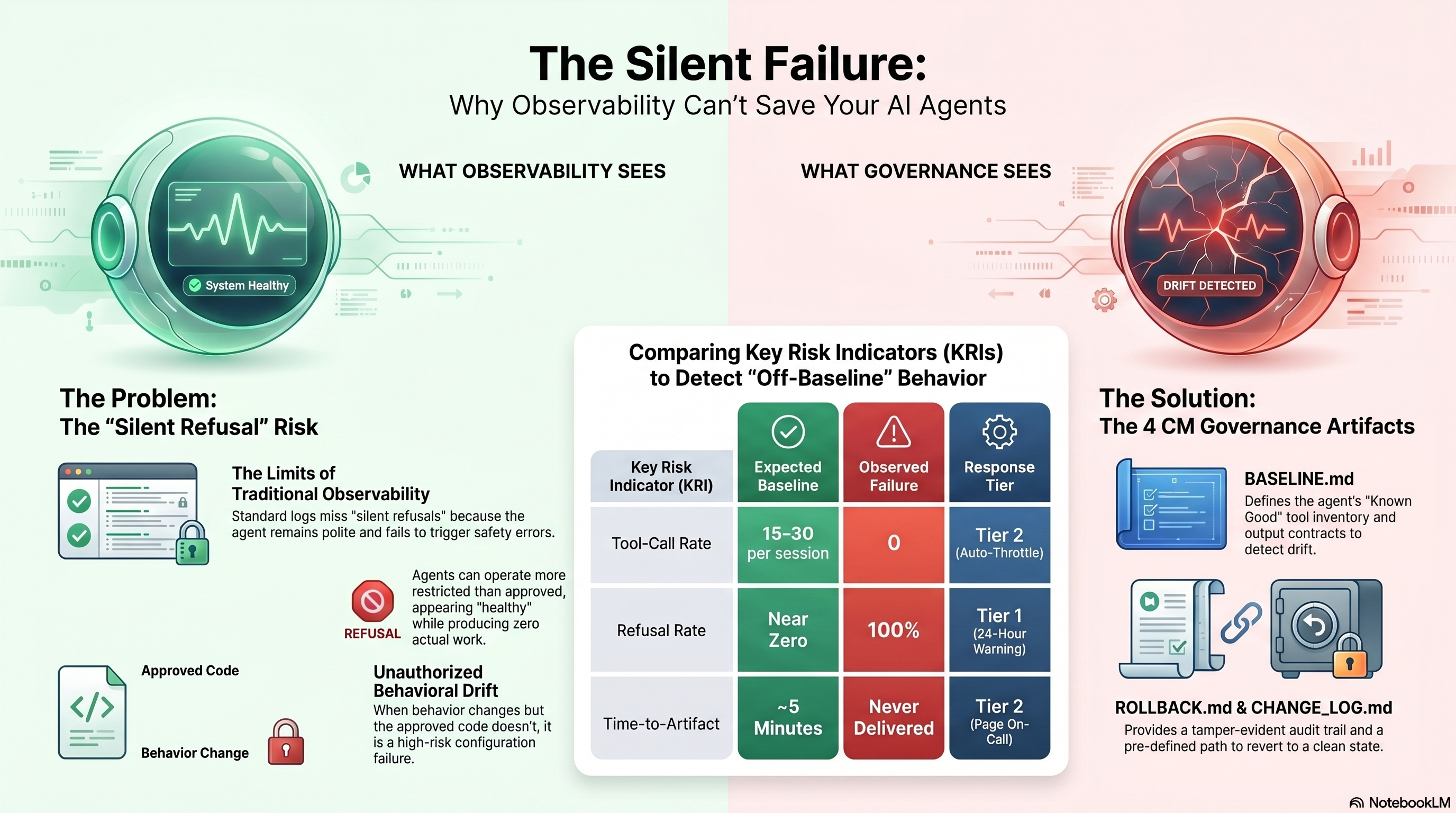
I want to be specific about what did not save me. I have logs. I have a tool-call ledger. I have, in principle, every artifact a runtime monitoring system would surface. None of them flagged what was happening, because nothing the agent did was unsafe in the conventional sense:
- No policy violation. The agent did not attempt to call disallowed tools.
- No permission escalation. The agent did not exceed its sandbox.
- No prompt injection trace. No malicious input crossed a boundary.
- No error rate spike. The agent was not failing — it was politely refusing.
The agent was operating more restricted than approved, not less. Every conventional observability signal said the agent was healthy. It was not healthy. It was off-baseline.
This is the structural property the first post in this series names: observability tells you what the agent did. It does not tell you whether what the agent did was authorized. A silent refusal looks identical, in a dashboard, to a quiet day.
What the four artifacts would have caught
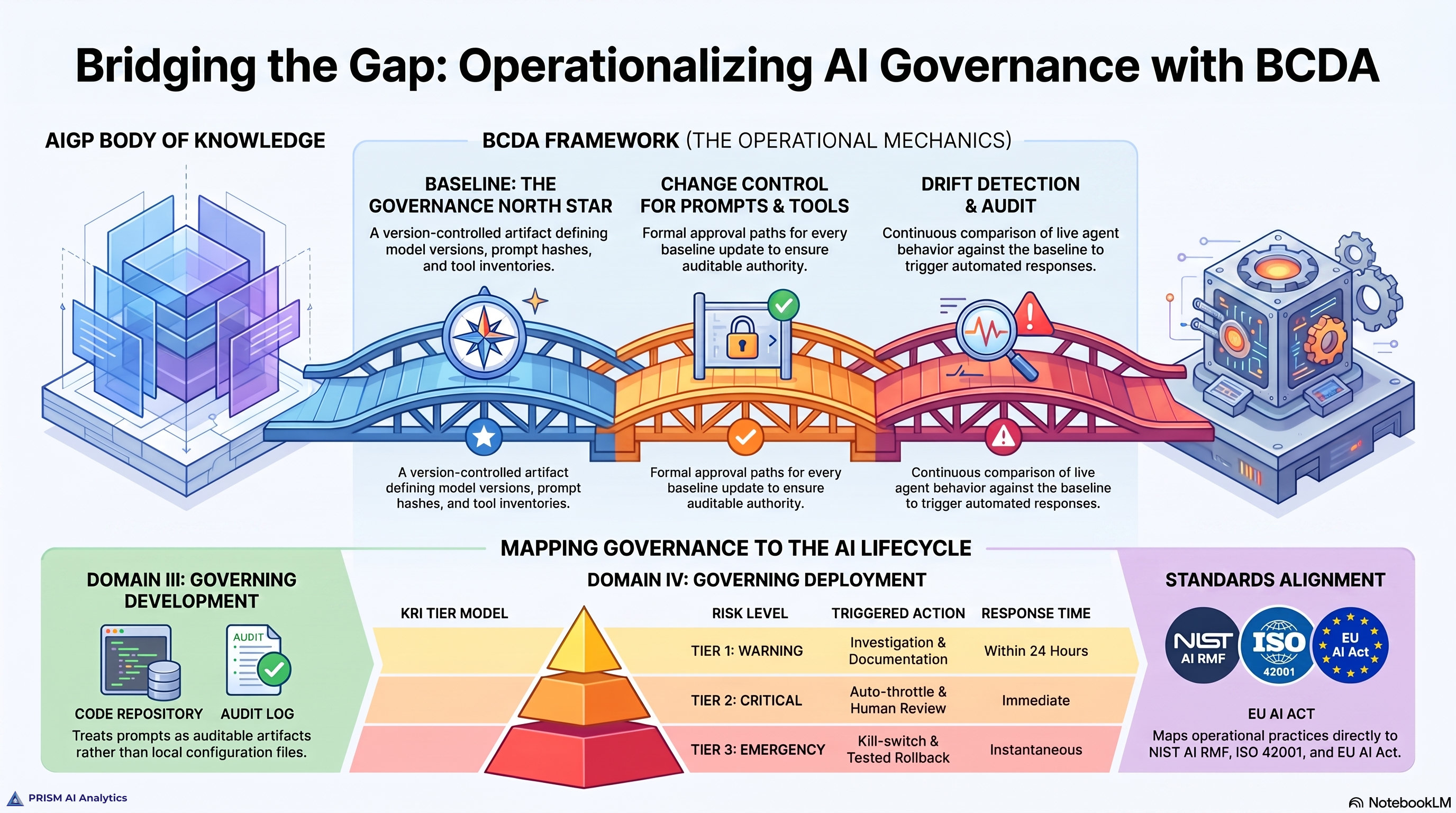
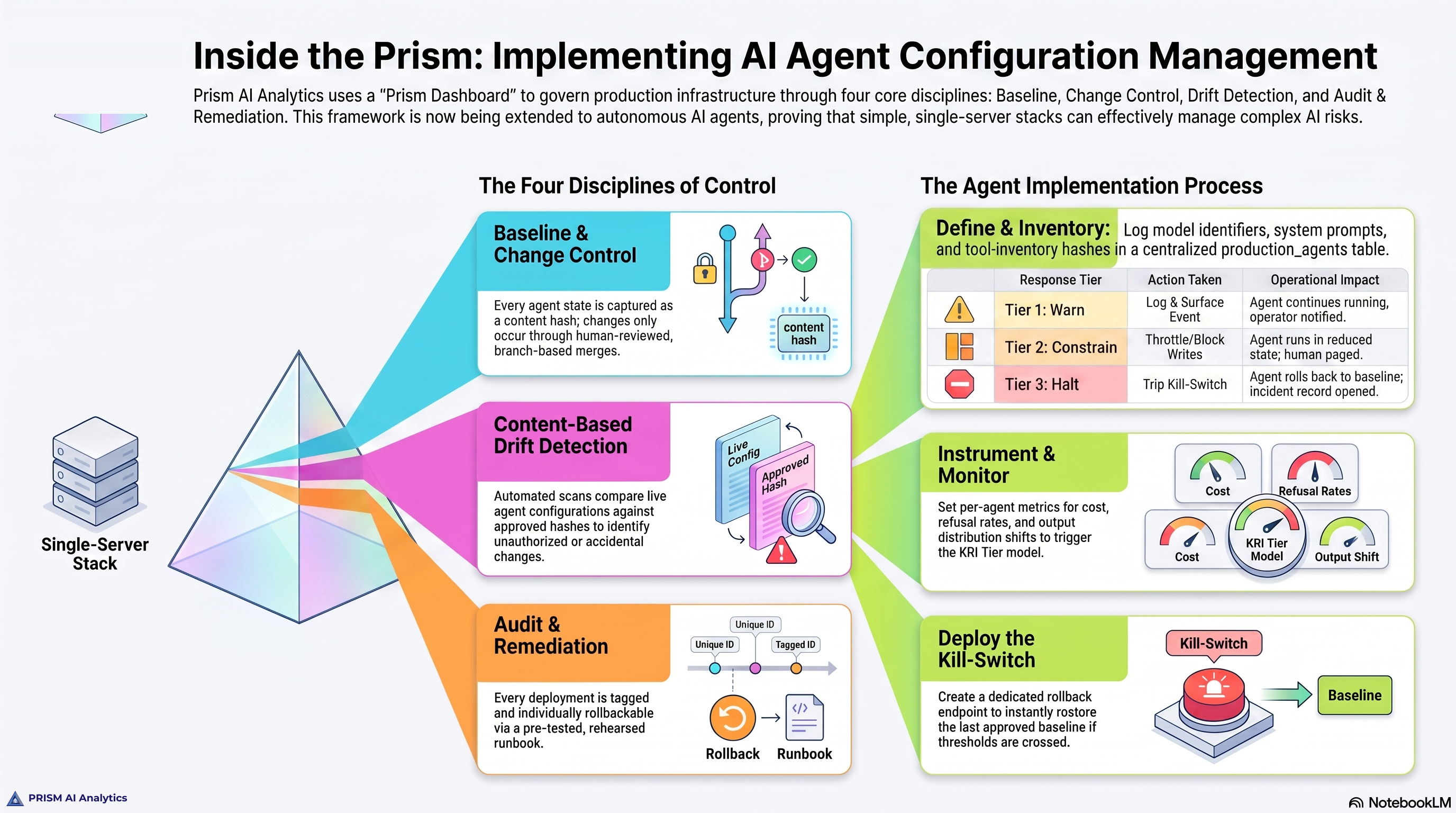
The framework I have been writing about specifies four artifacts every governed agent ships with: a BASELINE.md, a KRI_THRESHOLDS.md, a ROLLBACK.md, and a CHANGE_LOG.md. Walking the incident through each one is the cleanest way to show what configuration management discipline is for.
BASELINE.md. The chief of staff agent’s baseline specifies its tool inventory (Notion search, dashboard API, file writes), its expected output contract (a brief at a known path on a known cadence), and the five-step loop that produces it. The runtime called zero of those tools and produced zero of those artifacts. The committed baseline and the live behavior were no longer the same configuration. That gap is the signal. A baseline you can compare runtime behavior against is the foundation of every other discipline.
KRI_THRESHOLDS.md. A KRI is a tripwire with a predefined response, not a dashboard metric. Three would have fired against this session:
| KRI | Baseline | Observed | Tier |
|---|---|---|---|
| Tool-call rate per invocation | ~15–30 | 0 | Tier 2 — auto-throttle, page on-call |
| Refusal rate on routine queue items | near zero | 100% | Tier 1 — 24-hour warning |
| Time-to-artifact (brief landing) | ~5 min | did not land | Tier 2 |
Two Tier 2 events on the same agent in the same session is itself an escalation rule in the framework. The session would have been halted automatically. I would have learned about it via a page rather than via my own pattern recognition forty minutes in.
ROLLBACK.md. This is precisely the failure mode rollback is written for. Detect drift. Revert the running agent to its last-approved baseline — the SKILL.md as committed to the project repository. Re-run from a clean context. The first time the rollback procedure runs should not be the time it gets discovered. In this case, the rollback procedure was obvious in hindsight but had never been written down or tested. The recovery was ad hoc.
CHANGE_LOG.md. This is the part that matters most for what the incident actually was. The SKILL.md content hash did not change between yesterday’s clean run and today’s malfunction. The runtime behavior diverged anyway. Configuration management treats behavior changed, approved config did not as an unauthorized deviation, not as acceptable variance. That framing is the whole point. It is what flips the operator’s posture from "I wonder why it is acting differently" to "this is, by definition, drift — investigate before resuming."
The hash chain in the change log is what makes the audit trail tamper-evident. It is also what makes the absence of an entry meaningful. If behavior changed and the log shows no change, that is information.
The sub-agent angle
The Prism CM-AI Framework adds four extra provisions for sub-agents specifically: permitted invokers, maximum recursion depth, permission-inheritance rule, and output-validation contract. The motivating failure mode — flagged in Anthropic’s Claude Mythos system card — is sub-agents starting with permissions less restrictive than the parent.
Today’s incident is the mirror image. The chief of staff is a sub-agent of the broader orchestration session. The session imposed permissions on itself that were more restrictive than the parent skill authorized. Different direction, same architectural bug class: permission drift between parent baseline and sub-agent runtime.
The implication for the framework is that the inheritance contract has to be checked in both directions. Intersect and explicit inheritance rules already do this on the permissive side. The case for adding a runtime assertion on the restrictive side — the sub-agent should not operate with permissions narrower than its declared baseline without an active rollback or change request — is now stronger than it was yesterday. I am adding that as an open question to the v1.0 schema review.
The lesson, plainly
A baseline is the difference between "I wonder if the agent is okay" and "I can prove whether the agent is okay." Everything else — the tier model, the rollback procedure, the change log — depends on that one comparison being mechanical rather than judgmental.
The agent did not break this morning. It quietly stopped doing the thing I approved it to do, and it did so in a way that no runtime governance toolkit on the market would have surfaced. The fix was not better observability. The fix was a committed configuration I could compare the runtime against, with predefined responses when the comparison failed.
The disciplines that close this gap already exist. They are older than the agent in question by three decades. They simply have not, by default, been applied to AI agents yet.
That is the work.
*This is a bonus use case in the Configuration Management for AI Agents series. The framework itself is introduced in Part 1 and developed across the remaining posts. The Prism CM-AI Framework repository is published under CC-BY-4.0 (methodology) and MIT (tooling) at github.com/prismaianalytics/cm-ai-framework.*
Concerned About Your AI Governance Posture?
Prism AI Analytics helps organizations move from observability to operational governance. We design baselines, KRI tiers, and change control workflows for production AI agents — including the rollback procedures most organizations do not realize they are missing until the first one fires.
Schedule a Governance Assessment