Two recent signals are worth holding next to each other. Datadog’s *2026 State of AI Engineering* report, drawing on telemetry from more than a thousand Datadog customers running LLMs in production, finds that roughly five percent of all LLM call spans fail outright — with about sixty percent of those failures caused by capacity limits and rate-limit exhaustion. And in *Moffatt v. Air Canada*, a 2024 British Columbia Civil Resolution Tribunal decision, the airline was held liable when its public-facing chatbot fabricated a bereavement-fare policy that did not exist — the tribunal rejected the argument that the chatbot was a separate legal entity.
| Production AI today | Figure | Source |
|---|---|---|
| LLM call spans that fail outright in production | ~5% | Datadog, *2026 State of AI Engineering* |
| Of those failures, share caused by capacity / rate-limit exhaustion | ~60% | Datadog, *2026 State of AI Engineering* |
| Year of first major chatbot-liability tribunal ruling | 2024 | *Moffatt v. Air Canada*, BC CRT |

These are not failures of intent. Most of the organizations behind those numbers have AI governance policies. They have AI ethics committees. They have observability dashboards. They have, in many cases, six- and seven-figure investments in vendor platforms that were sold as governance solutions.
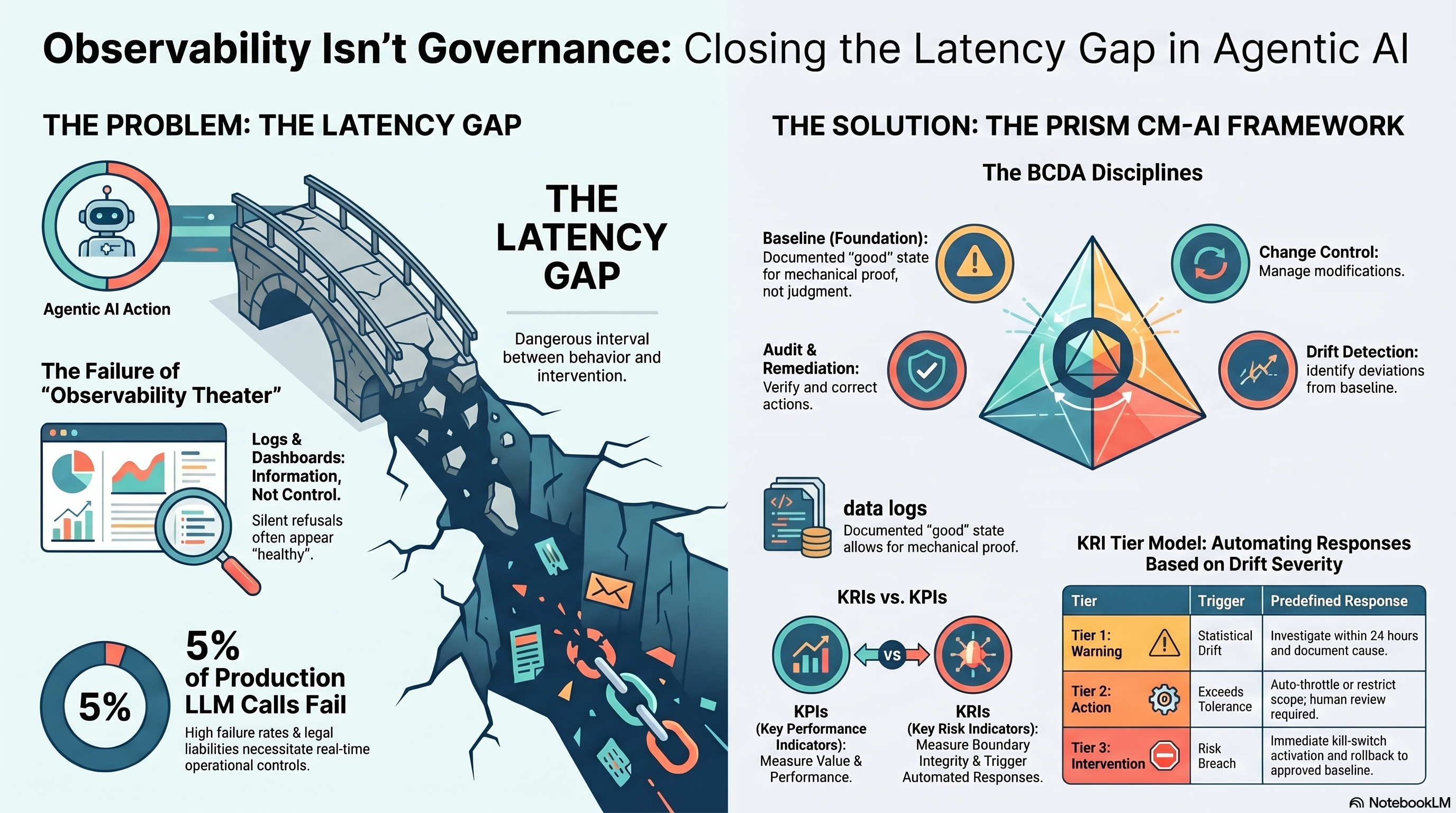
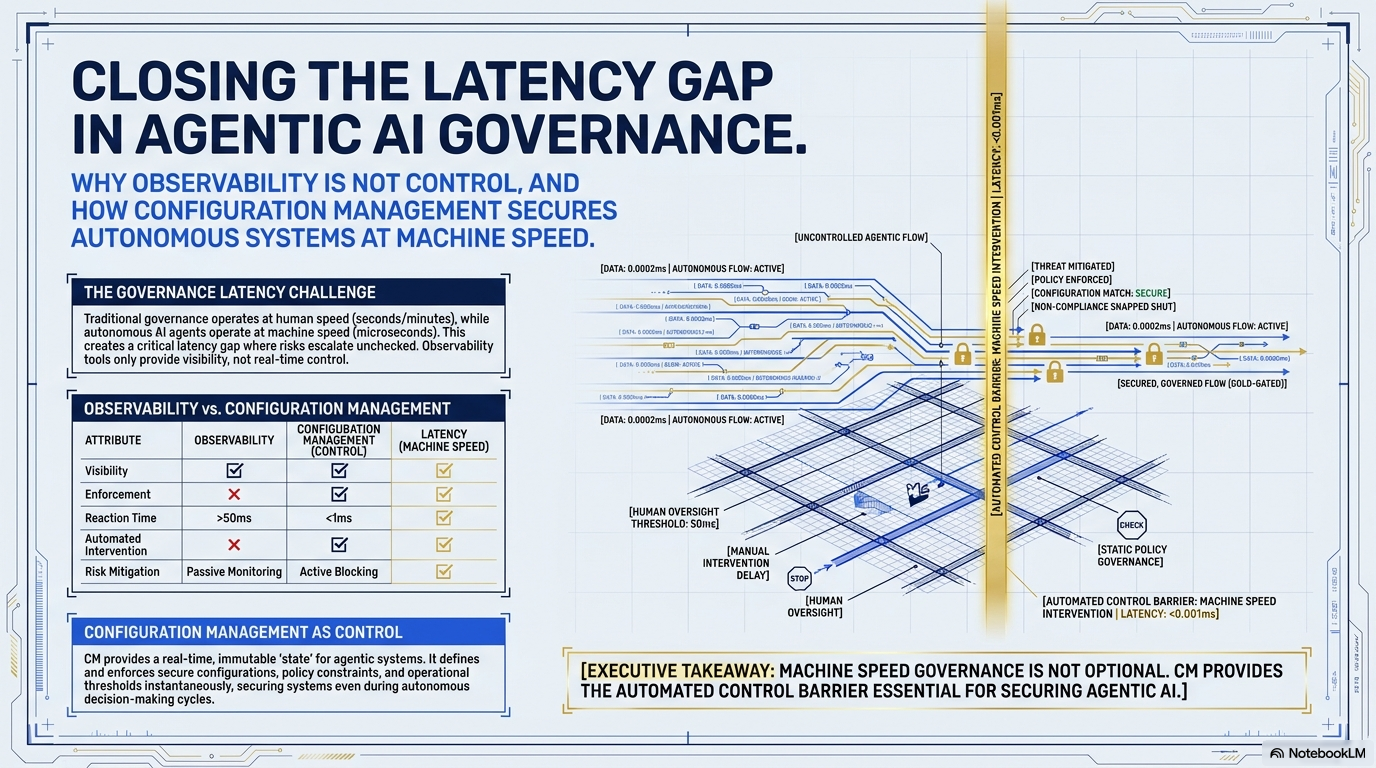
What they do not have is a way to detect, in real time, that an autonomous agent has stopped behaving the way they approved it to behave. That gap — between the speed at which agents act and the speed at which humans notice — has a name. It is the latency gap. And it is the central problem in agentic AI governance today.
What observability actually does
Observability tools watch what AI agents produce. They log inputs, outputs, tool calls, and handoffs. They generate traces. They surface dashboards. Done well, they provide the forensic record an organization needs after something goes wrong — what did the agent do, and when, and why?
Observability is necessary. It is not the same as governance.
A dashboard that shows the agent’s hallucination rate climbed to 4 percent over the last hour is not, by itself, a control. It is information. Whether anything happens in response depends on whether someone is watching the dashboard, whether they recognize the deviation as actionable, whether they have the authority to intervene, and whether they can act faster than the agent is acting. In production, those conditions are rarely met.
Oracle’s recent guidance on enterprise agentic AI puts the distinction more bluntly: observability is not governance. I call the dominant industry pattern observability theater — the practice of building elaborate monitoring infrastructure that produces a feeling of control without producing actual control.
That framing is uncomfortable, because it implicates a lot of recent investment. It is also accurate.
The latency gap, defined
Consider what happens when an autonomous agent’s behavior shifts. Maybe the underlying model received a routine update from the provider. Maybe a prompt was edited to handle a new edge case and the change rippled into unintended behavior elsewhere. Maybe a tool the agent calls returned data in a slightly different format and the agent’s interpretation drifted. Maybe a user discovered a prompt injection that the agent’s policy classifier does not yet catch.
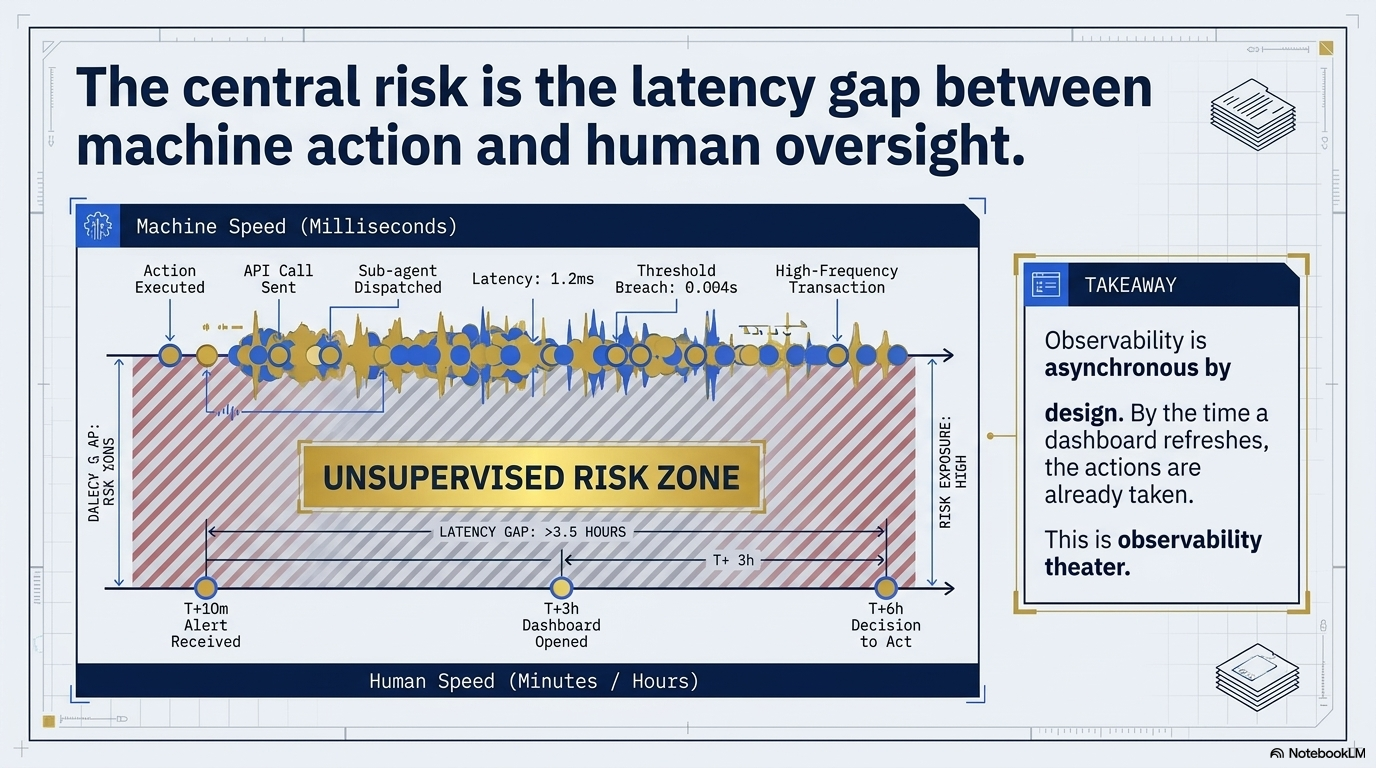
In each case, there is an interval between the moment the agent’s behavior changes and the moment a human, looking at a dashboard, notices and decides to act. That interval is the latency gap.
The agent operates at machine speed. It can complete thousands of actions in the time it takes a human reviewer to refresh a dashboard. By the time the dashboard refreshes, the actions have already been taken — emails sent, transactions processed, customers responded to, decisions logged. Even when the human notices and intervenes, the intervention is reactive. The damage, if any, is in the past.
This is not a flaw in observability tools. It is a structural property of using human attention to monitor superhuman speed. Observability cannot close the latency gap on its own. It is asynchronous by design.
What does close the gap
The disciplines that close latency gaps already exist. They are not new. They are, in fact, older than the AI governance conversation by decades.
In financial services, banks have been required for thirty years to operate Key Risk Indicator frameworks. A KRI is not a dashboard metric. It is a tripwire — a defined threshold attached to a defined action. When a metric crosses the threshold, the action fires automatically: the trading desk is throttled, the credit line is frozen, the transaction is held for review. The discipline is what allows the organization to operate at the speed of its trading systems rather than the speed of its compliance reviewers.
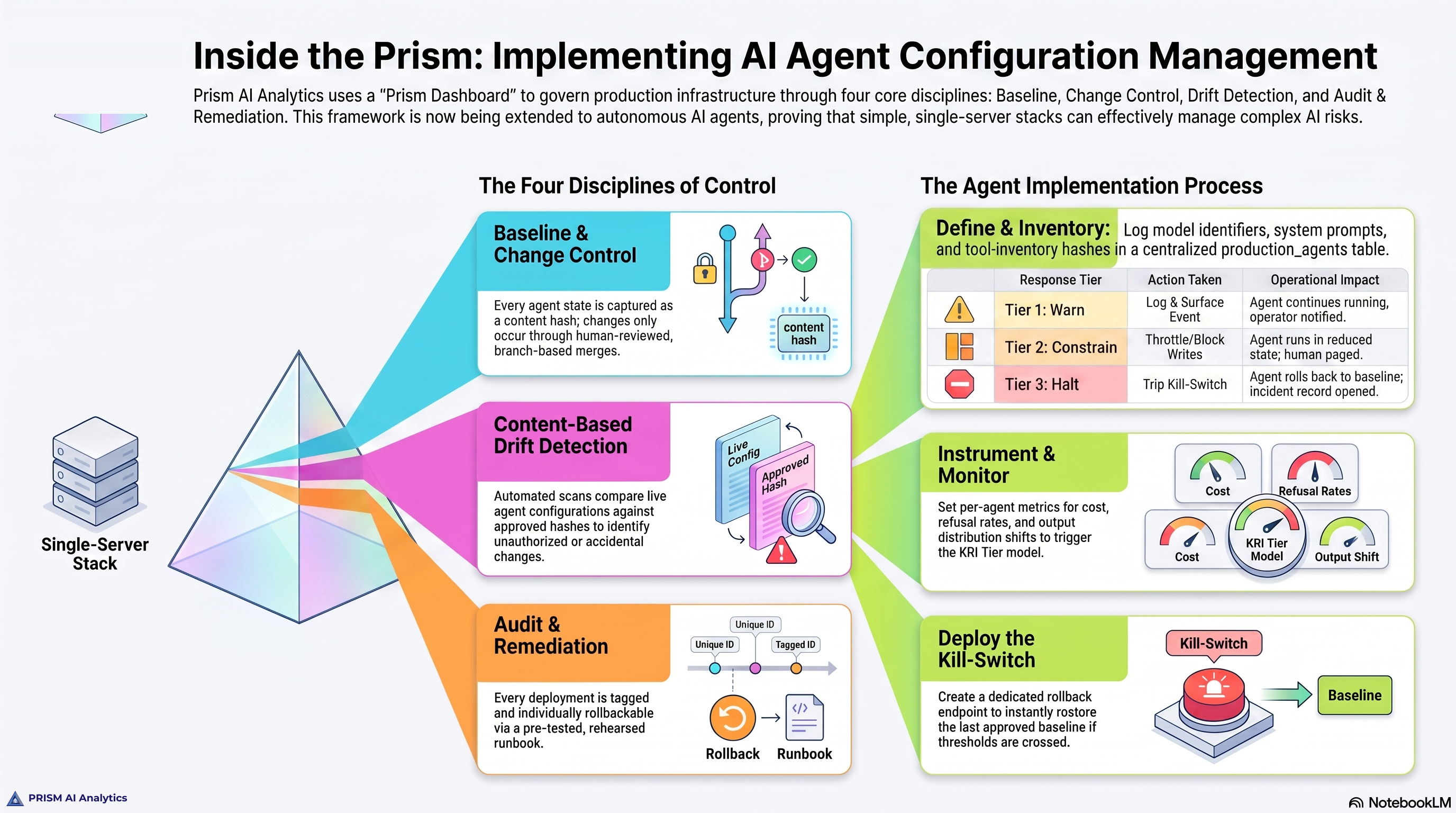
In configuration management, enterprise IT has run a parallel discipline for the same length of time. Every system has a documented baseline. Every change to that baseline goes through change control. Drift between the live state and the approved baseline is detected automatically and either remediated or escalated. The audit trail is contemporaneous with the change, not reconstructed from logs after an incident.
Critical infrastructure operates on the same logic. Power grids, air traffic control, and pipeline networks do not rely on humans watching screens. They rely on automated control loops with predefined thresholds and predefined responses. Human attention is reserved for the cases the automation flags as needing human judgment — not for the routine work of keeping the system inside its approved envelope.
Each of these disciplines does the same thing in different language. They define what good looks like. They detect deviation from good automatically. They respond to deviation at the speed of the system being governed, not the speed of the people governing it.
That is what AI agent governance needs. And it is what most current AI agent deployments do not have.
What the vendor stack covers, and what it does not

It is fair to ask whether the major AI vendors are providing this discipline. The honest answer is: partially.
Anthropic’s Responsible Scaling Policy defines AI Safety Levels — graduated baselines tied to capability thresholds that, when reached, trigger stronger safeguards. Anthropic holds ISO/IEC 42001 and SOC 2 Type II certifications. Internally, the discipline is real and documented. But the framework is for the model itself, not for the agent an enterprise builds on top of it.
OpenAI’s recently published Agentic Governance Cookbook treats policies as code, distributes them as installable packages, and traces every LLM call and tool execution. Headline framing: governance drives delivery. That is the right posture. But the cookbook covers policy distribution and post-facto evaluation. It does not cover real-time threshold-based intervention, change control workflows for the policy itself, or rollback when something goes wrong.
Microsoft and AWS are introducing the language of control planes for AI agents — registries, identity, access control, interoperability. That work is necessary. It is also identity- and perimeter-led. It controls what an agent can touch. It does not, on its own, control whether the agent is still doing what was approved.
The gap is consistent across the vendor stack: real-time configuration management. Baselines that are continuously checked against the live agent. Drift detection that fires at machine speed. KRIs with predefined intervention paths. The audit trail that proves, to a regulator or a board, that the agent now operating on behalf of the organization is materially the same agent that was approved to operate on behalf of the organization.
Closing that gap is not a tooling problem. It is a discipline problem. The tools exist. The discipline has not been named.
The discipline has a name
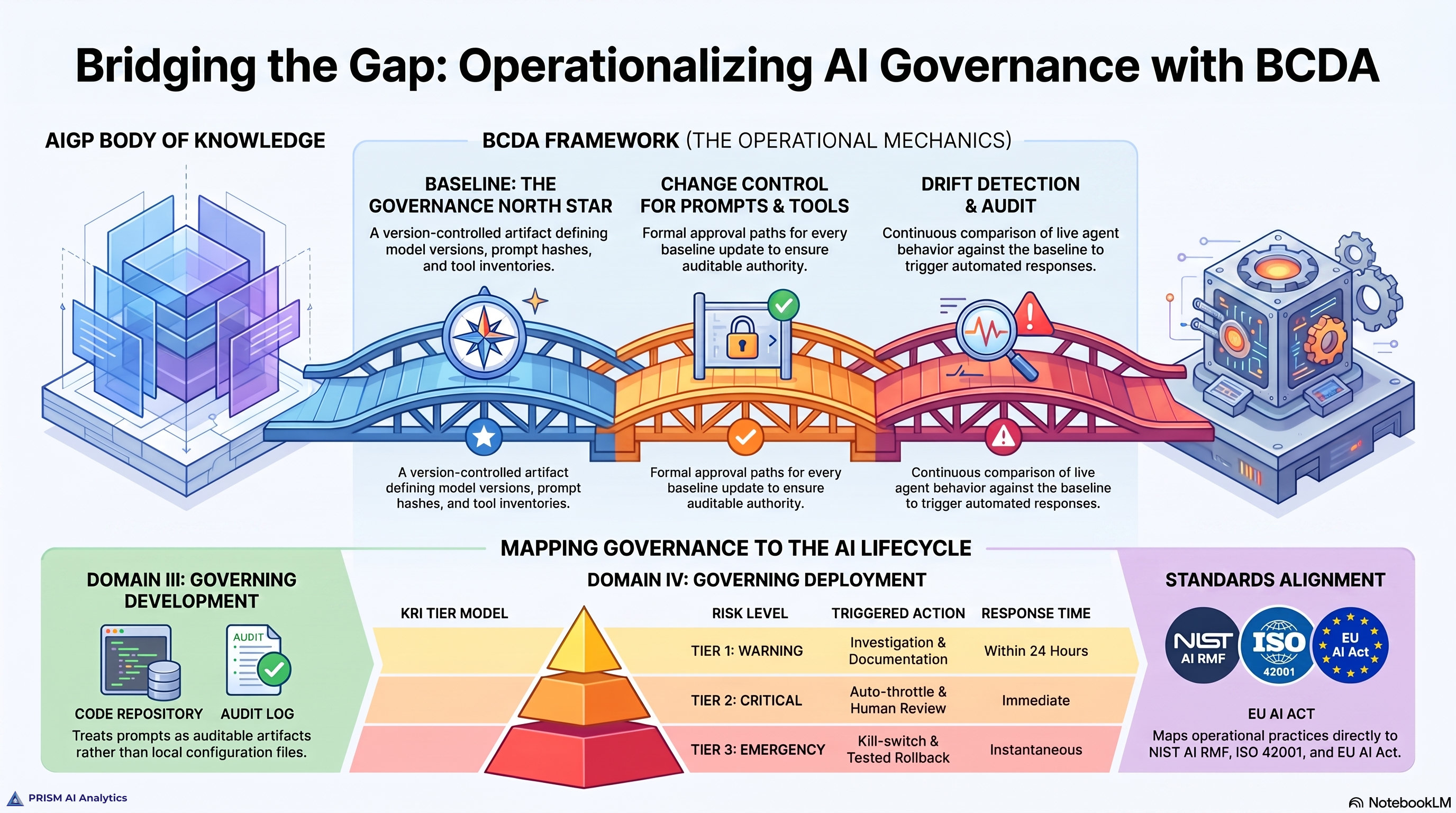
It is configuration management. It is the operational layer enterprise IT has used to govern systems for thirty years. Applied to AI agents, it has four parts: a documented baseline for every production agent; a change control path that includes the prompt, the tool inventory, and the data scope; drift detection that runs at the speed of the agent; and an audit and remediation discipline that ties any agent action to the baseline that authorized it.
Layered over those four parts is the KRI tier model from financial services: tripwires with predefined responses, tuned to the agent’s actual baseline rather than to vendor defaults.
This is not a novel framework. It is the explicit naming of what works. The argument of this series is that AI governance, as currently practiced, is missing the operational twin of the policies it has spent the last three years writing.
The next post in this series introduces the framework directly: the four configuration management disciplines, the three delivery layers Prism uses to operationalize them, and the KRI tier model. If you want the short version, the position is this: the disciplines that worked for systems work for agents. They do not need to be reinvented. They need to be named, ported, and applied.
A dashboard tells you the building is on fire. A control plane prevents arson. Configuration management is the difference.
\*This is part 1 of a six-part series on Configuration Management for AI Agents. Part 2 introduces the Prism CM-AI Framework. Subscribe via the Prism newsletter to receive each installment.\*
Sources cited
- Datadog, 2026 State of AI Engineering. datadoghq.com/state-of-ai-engineering
- Moffatt v. Air Canada, BC Civil Resolution Tribunal (2024). Case summary at mccarthy.ca/en/insights/blogs/techlex/moffatt-v-air-canada-misrepresentation-ai-chatbot
- Oracle, Runtime Governance for Enterprise Agentic AI. blogs.oracle.com/ai-and-datascience
- Anthropic, Responsible Scaling Policy v3.0 (effective 2026-02-24). anthropic.com/responsible-scaling-policy
- Anthropic, Trust Center — certifications and audit material. trust.anthropic.com
- OpenAI, Agentic Governance Cookbook. developers.openai.com/cookbook/examples/partners/agentic_governance_guide/agentic_governance_cookbook
Concerned About Your AI Governance Posture?
Prism AI Analytics helps organizations move from observability to operational governance. We design baselines, KRI tiers, and change control workflows for production AI agents.
Schedule a Governance Assessment