The phrase AI agent governance means different things in different conversations. A CISO at a financial-services firm hears "perimeter and identity." A compliance officer hears "policy and audit." An ML engineer hears "evaluation and observability." A risk officer hears "operational controls and escalation." When the people in a room each define a foundational term differently, they will produce frameworks that do not connect to each other, audit trails that do not reconcile, and incident response plans that contradict each other under pressure.
This post is the primer for a six-part series on configuration management for AI agents. The rest of the series goes deep on specific disciplines — the latency gap, the four BCDA disciplines, the KRI tier model, the standards crosswalks, a working implementation, and the AIGP Body of Knowledge mapping. Before any of that, the terms need to mean the same thing twice in a row.
What follows is a working glossary plus the Prism CM-AI Framework’s specific definitions, organized so each definition builds on the ones above it.
What AI Agent Governance is, and what it is not
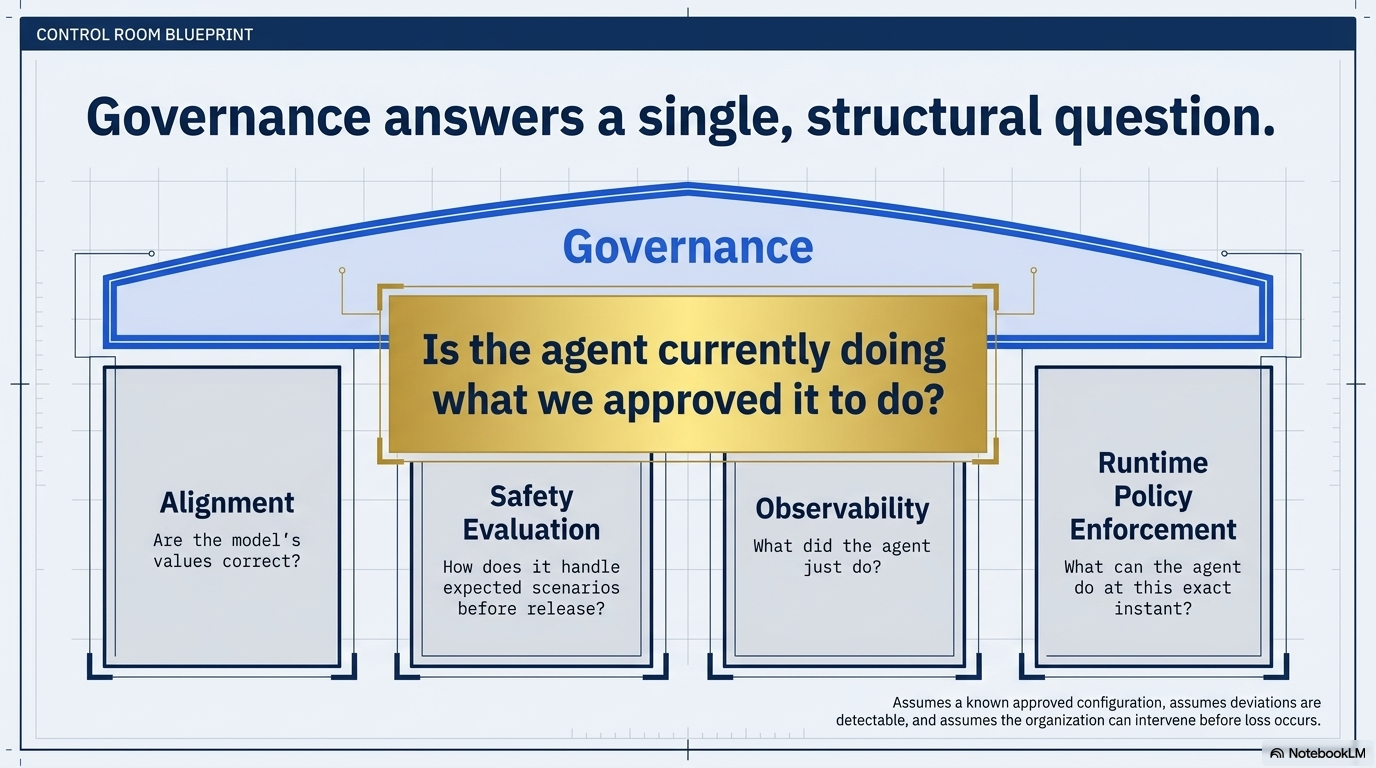
AI agent governance is the operational discipline of ensuring that autonomous AI systems acting on behalf of an organization continue to operate within the boundaries the organization approved. It answers a single question: is the agent currently doing what we approved it to do?
That question has structure. It assumes there is an approved configuration. It assumes deviation from that configuration is detectable. It assumes the organization can intervene before deviation becomes loss. Each of those assumptions is a discipline, not a tool.
AI agent governance is not alignment research. Alignment asks whether the model’s values are correct in the first place. Governance assumes the model passed an alignment review at deployment time and addresses what happens after.
It is not safety evaluation. Evaluation tests an agent against expected scenarios. Governance handles unexpected scenarios, drift between expected and actual behavior, and the audit trail that supports incident response.
It is not observability. Observability tells you what the agent did. Governance tells you whether what the agent did was authorized.
It is not runtime policy enforcement on its own. Policy enforcement decides what an agent can do at this instant. Governance decides what an agent is supposed to be allowed to do, who approved that, when it changed, and whether the live policies still match the approved configuration.
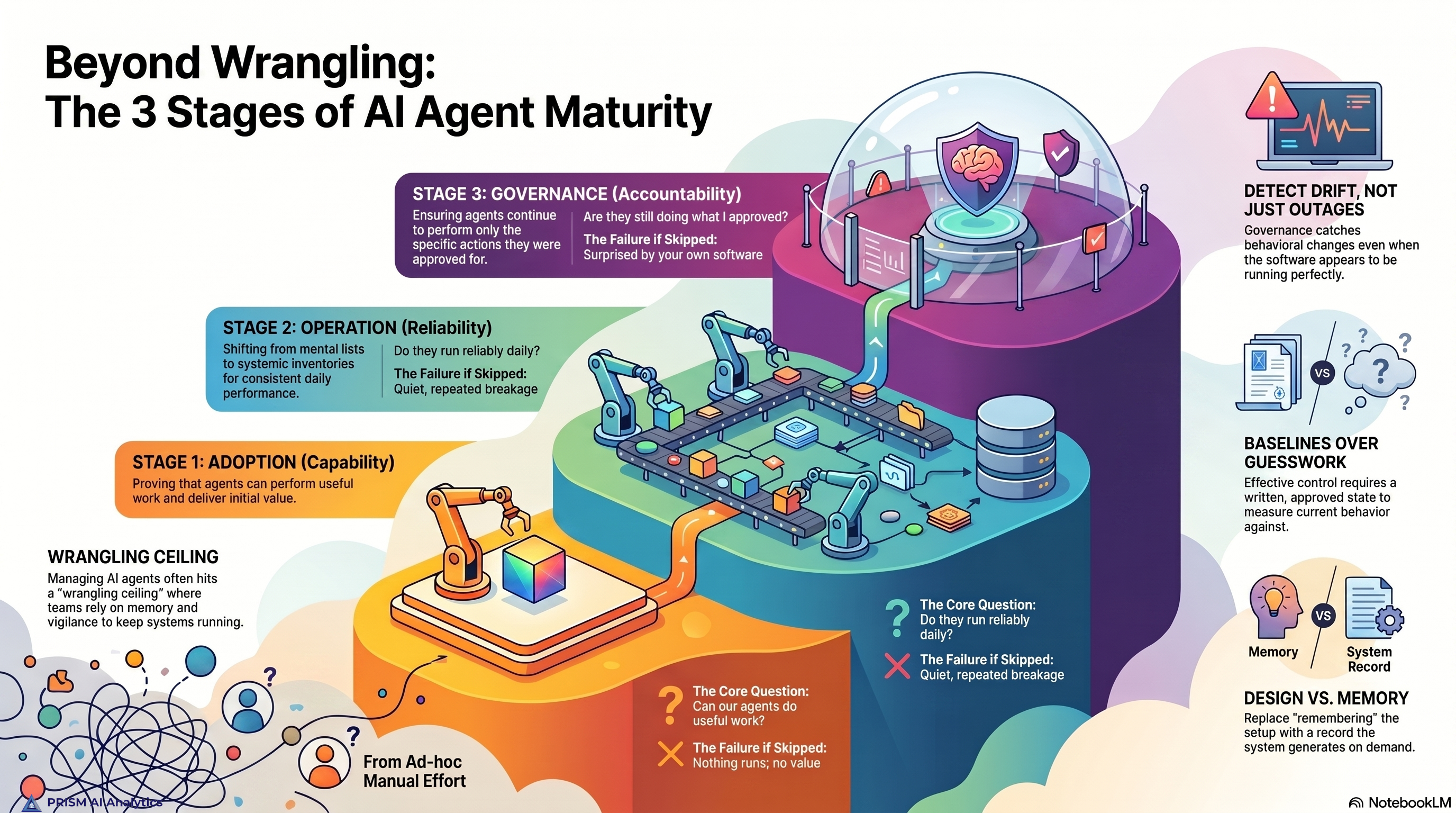
Agentic AI differs from earlier AI systems in one operationally critical way: it acts. Static prediction models output probabilities. Agentic systems take actions — send emails, modify records, execute trades, file tickets, generate code. Action means consequence. Consequence means the governance bar moves up.
The latency gap
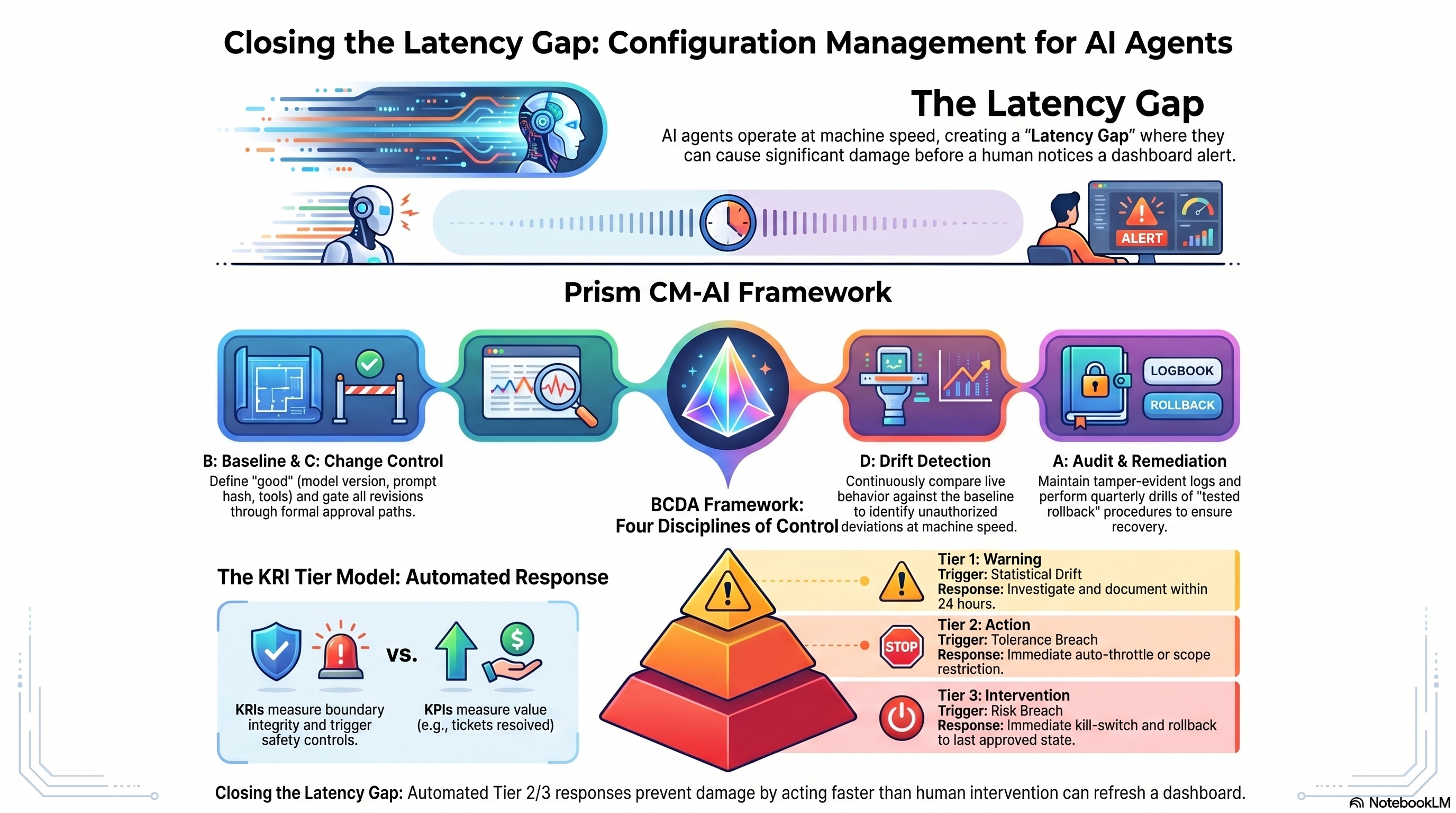
The central problem in agentic AI governance is the latency gap — the interval between the moment an agent’s behavior changes and the moment a human, looking at a dashboard, notices and decides to act.
Agents operate at machine speed. They complete thousands of actions in the time it takes a human reviewer to refresh a screen. By the time the dashboard refreshes, the actions are already taken. Even when the human notices and intervenes, the intervention is reactive. The damage, if any, is in the past.
Observability cannot close the latency gap on its own. It is asynchronous by design. What closes the gap is automated detection of deviation from an approved baseline, with predefined responses tiered to severity. That is what configuration management has done in adjacent fields — enterprise IT, financial services, critical infrastructure — for three decades. The framework presented in this series ports that discipline to AI agents.
The four BCDA disciplines
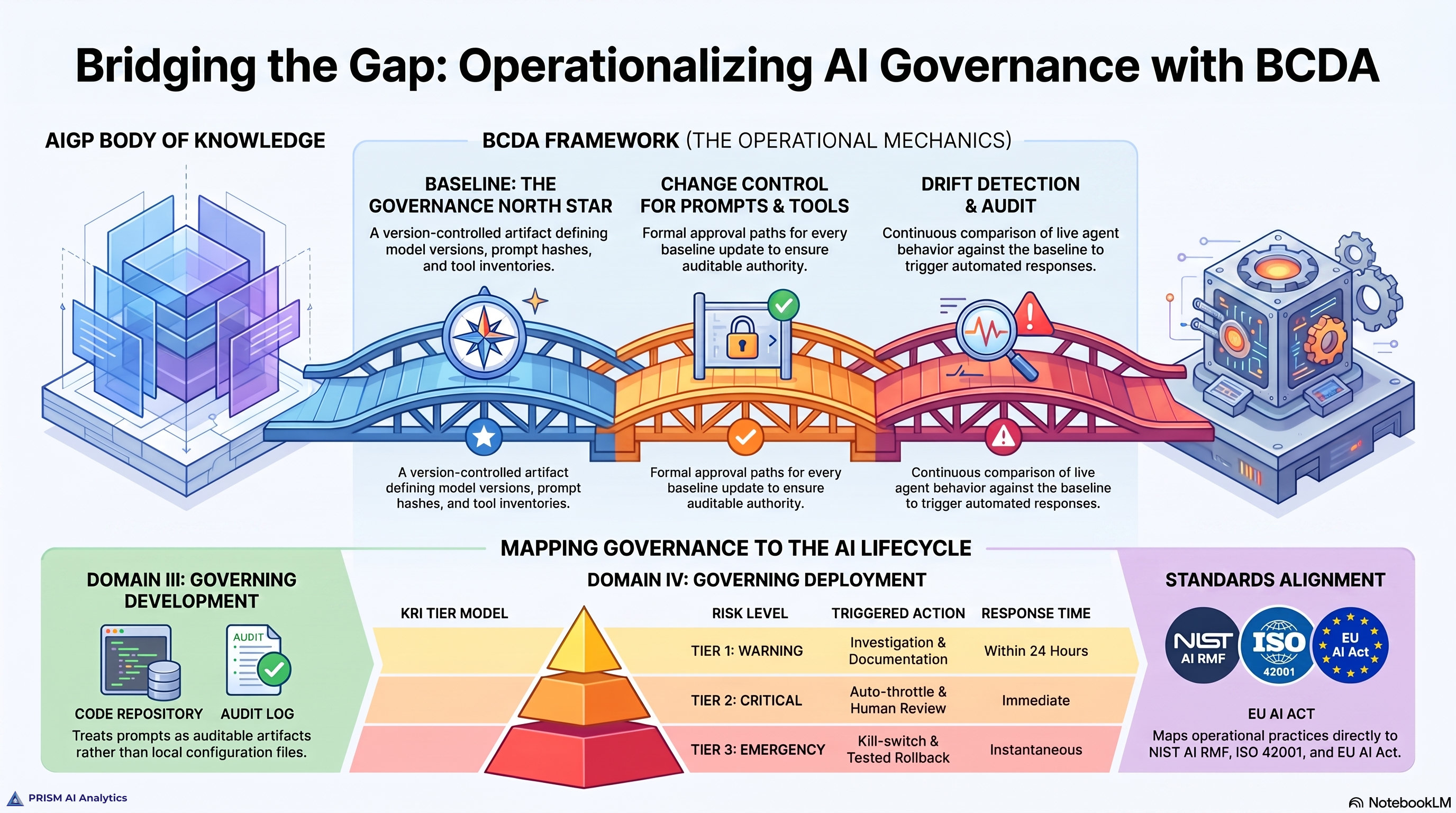
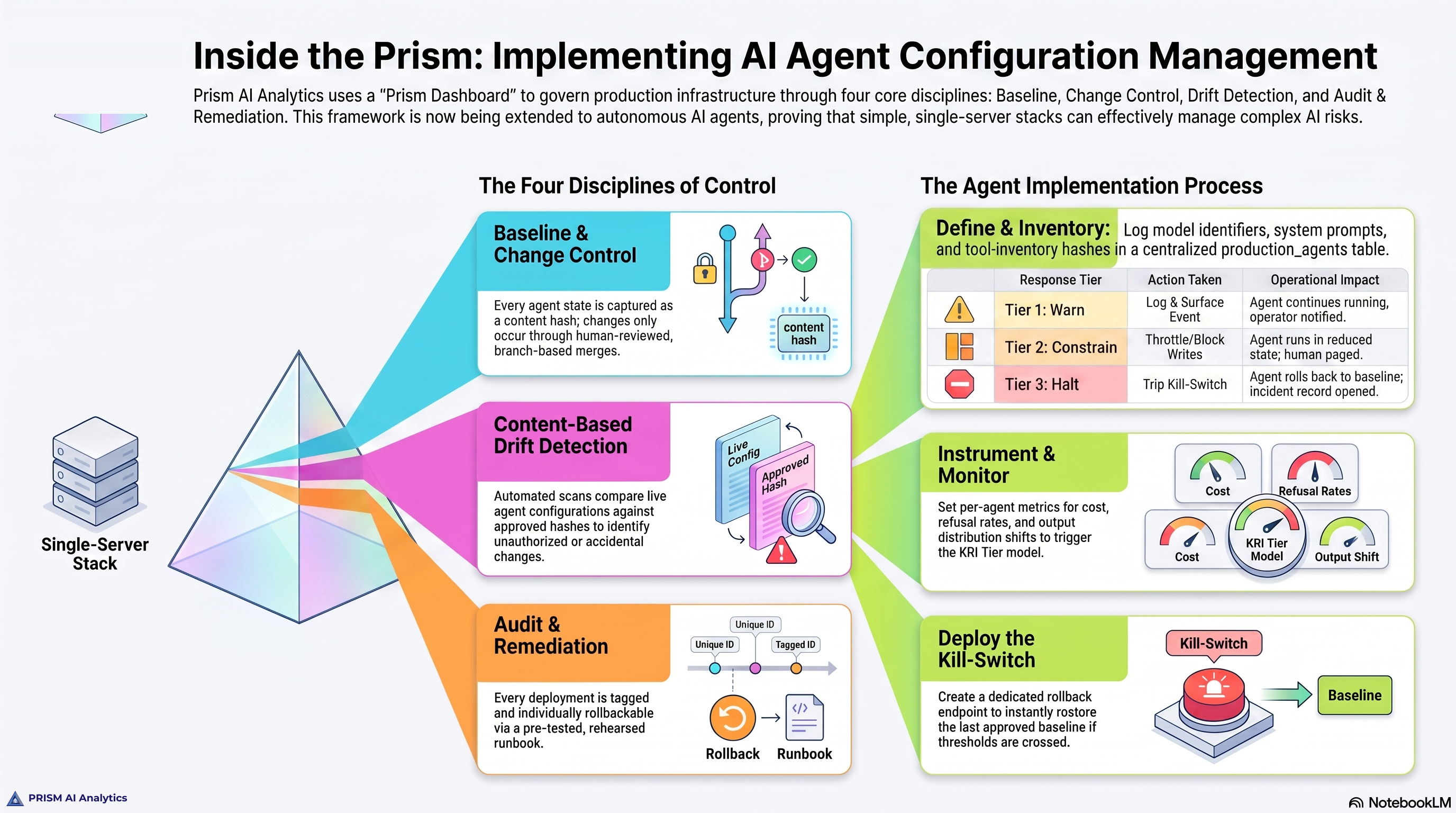
Configuration management as a discipline has four parts. Each is necessary; none is sufficient on its own. The framework names them BCDA — short for Baseline, Change Control, Drift Detection, Audit and Remediation.
Baseline is the documented description of what good looks like for an agent. For a production AI agent, the baseline includes the approved model identifier and version, the system prompt’s content hash, the inventory of tools the agent may invoke, the data resources the agent may access, the expected output distribution from a 14- to 30-day observation window, the latency band, the refusal rate baseline, and the cost-per-action target. The baseline is version-controlled, signed off by a named approver, and reviewed quarterly. Without a baseline, drift is undetectable.
Change Control is the defined approval path for any modification to the baseline. Most current AI deployments are weakest here. Organizations gate model upgrades but rarely gate prompt revisions. They gate new tool integrations but rarely gate scope expansions to existing tools. Change control extends approval discipline to every element of the baseline — the prompt, the tool inventory, the data scope. The approval path is documented, the audit trail captures who approved what against what evidence, and the rollback path is defined before the change is approved, not after.
Drift Detection is continuous comparison of the live agent’s behavior against the baseline, at machine speed, with defined thresholds and predefined responses. Drift detection is not a dashboard. It is an automated control loop that emits events when behavior deviates from the documented baseline. Two patterns matter: exact-match comparison for elements that should not change without approval (model version, prompt hash, tool whitelist, data scope) and statistical comparison for elements that fluctuate naturally within tolerance (output distribution, latency, refusal rate, cost-per-action).
Audit and Remediation is the ability to reconstruct, after any event, exactly what the agent did against what baseline, who approved that baseline, and what changed between then and now. Combined with the ability to roll back to a previously approved baseline when the response to drift is to revert. The audit trail uses hash chains — the same property git commits provide for code, applied to configuration state — so that tampering is detectable. The rollback procedure is tested on a non-production replica before the agent enters production and re-exercised at least quarterly.
The disciplines exist whether or not anyone names them. The framework’s contribution is the explicit naming, the cross-discipline integration, and the operational thresholds for each.
| Discipline | Question it answers | What it looks like for an AI agent |
|---|---|---|
| B — Baseline | What is good supposed to look like? | Approved model + version, system prompt hash, tool inventory, data scope, expected output distribution, latency band, refusal rate, cost per action |
| C — Change Control | Who can change the baseline, when, with what authorization? | Prompt revisions, model upgrades, tool additions, data-source expansions — each routed through a defined approval path |
| D — Drift Detection | Has runtime diverged from baseline? | Output distribution shifts, hallucination-rate thresholds, tool-call error spikes, cost drift, refusal-rate inversion, anomaly detection |
| A — Audit & Remediation | Can we reconstruct why? Can we roll back? | Decision provenance, prompt + tool-call logs, change history with hash chain, kill-switch, tested rollback, post-incident review |
The KRI tier model
Drift detection on its own produces alerts. Alerts without a defined response are noise. The framework layers a Key Risk Indicator tier model over the drift detection discipline to turn alerts into actual controls.
The vocabulary matters. A KPI — Key Performance Indicator — measures whether the agent is producing value. Output volume, conversion lift, hours saved, cost reduction. A KRI — Key Risk Indicator — measures whether the agent is operating within its approved boundaries. Hallucination rate, refusal-rate inversion, output distribution shift, tool-call error rate. The two answer different questions and trigger different responses. A high-performing agent producing harmful or out-of-policy outputs is the worst possible failure mode, and it is largely invisible to a KPI dashboard.
The tier model has three levels, adapted from financial-services operational risk practice — specifically the discipline banks have run under SR 11-7 and OCC Bulletin 2011-12 since 2011.
Tier 1 — Warning. Statistical drift detected. The metric has moved outside the expected band but has not exceeded operational tolerance. Response time: investigate within 24 hours. Action: document the cause. If intentional, update the baseline. If unintentional, remediate. Authority: engineering or operations on-call.
Tier 2 — Action. Drift exceeds operational tolerance. The metric is materially outside the approved range. Response time: immediate. Action: auto-throttle, rate-limit, or restrict the agent’s scope. Human review required before continued operation. Authority: engineering manager or compliance lead.
Tier 3 — Intervention. Operational risk threshold breached. The agent’s behavior is materially outside what the organization can defensibly explain to a regulator, auditor, or board. Response time: immediate. Action: kill-switch activates. Rollback to last approved baseline. Incident report filed. Post-incident review within five business days. Authority: pre-defined incident commander; legal and executive notification required.
| Tier | Trigger | Response time | Action | Authority |
|---|---|---|---|---|
| Tier 1 — Warning | Statistical drift, within tolerance | Within 24 hours | Investigate; update baseline or remediate | Engineering or ops on-call |
| Tier 2 — Action | Drift exceeds tolerance | Immediate | Auto-throttle; human review required | Engineering manager or compliance lead |
| Tier 3 — Intervention | Operational risk threshold breached | Immediate | Kill-switch; rollback; incident report; review within 5 days | Pre-defined incident commander; legal + exec notification |
The tier model is what allows governance to operate at the speed of the agent rather than the speed of human attention.
How these terms relate to the major standards
The framework is designed to operationalize the policy outcomes the standards your compliance team is already accountable to require, not to replace them.
**NIST AI Risk Management Framework** — four functions: Govern, Map, Measure, Manage. BCDA disciplines map directly. Govern is change control. Map is baseline. Measure is drift detection plus the KRI catalog. Manage is audit and remediation plus tested rollback.
**ISO/IEC 42001:2023** mandates a Plan-Do-Check-Act cycle for AI management systems. BCDA disciplines operationalize the cycle: Plan equals Baseline, Do equals Change Control, Check equals Drift Detection, Act equals Audit and Remediation.
**EU AI Act, Article 72** requires post-market monitoring for high-risk AI providers with documented baselines. The KRI tier model plus the audit trail satisfy the operational evidence requirement.
**IAPP AIGP Body of Knowledge, Domains III and IV** — governance of AI development and deployment. The framework is the operational implementation layer of what these domains describe as governance accountabilities. Domain II’s standards crosswalks map cleanly to the BCDA × NIST × ISO × EU correspondences above.
How these terms relate to the runtime layer
The framework sits above the runtime governance toolkits already shipping in 2026, not against them. Specifically:
**Microsoft Agent Governance Toolkit** is the runtime kernel — policy enforcement at request time, identity verification, sandboxing, SRE practices. The framework provides the configuration-management layer above the kernel. The kernel decides what an agent is allowed to do right now; the framework decides what the kernel should be enforcing in the first place and when the rules should change.
**Palo Alto Networks Prisma AIRS** and the broader Cortex platform provide security-perimeter governance — authority delegation, identity boundaries, runtime controls. The framework adds the quantitative KRI tier model, baseline-definition methodology, and change-authorization workflow that the perimeter-security framing does not specify.
**GitAgent** provides git-native agent identity, behavioral constraints, and compliance metadata. The framework adds formal hash-chained CHANGE_LOG, KRI tier thresholds, tested rollback as a first-class artifact, and the financial-services lineage. Both can co-exist; agents written under GitAgent’s structure can adopt the framework’s four artifacts alongside their existing files.
The bonus post in this series — Microsoft’s Agent Governance Toolkit Is the Kernel. Configuration Management Is the Layer Above It. — goes deeper on the integration patterns. The short version: runtime engines and configuration management are complementary disciplines, not competing ones.
Glossary — quick reference
For readers who want to scan: every key term used in the series, defined in one line.
Agent. An AI system that plans, decides, and executes actions toward a goal, with access to tools and data, operating over multiple steps.
Audit and Remediation. The fourth BCDA discipline — reconstructing what the agent did against what baseline, with a tested path to roll back.
Baseline. The documented description of what good looks like for an agent — model version, prompt hash, tool inventory, data scope, behavioral expectations.
BCDA. Acronym for the four configuration management disciplines: Baseline, Change Control, Drift Detection, Audit and Remediation.
Change Control. The second BCDA discipline — defined approval path for any modification to the baseline.
Configuration Drift. The gap between the documented baseline and the live state of the agent.
Drift Detection. The third BCDA discipline — continuous comparison of live behavior against baseline, with defined thresholds.
Hash Chain. A sequence of cryptographic hashes where each entry references the prior entry, producing a tamper-evident audit trail.
KPI (Key Performance Indicator). A metric that measures whether the agent is producing value. Reviewed weekly or monthly. Action: optimize.
KRI (Key Risk Indicator). A metric that measures whether the agent is operating within approved boundaries. Monitored continuously. Action: escalate per tier.
Latency Gap. The interval between a behavioral change in an agent and a human noticing and intervening. The central problem the framework addresses.
**OWASP Top 10 for Agentic Applications.** The OWASP Gen AI Security Project’s canonical risk taxonomy for agentic AI systems — ten categories (ASI01–ASI10) released December 2025 for the 2026 edition.
Rollback. Reverting an agent to a previously approved baseline. Tested before production, re-exercised quarterly.
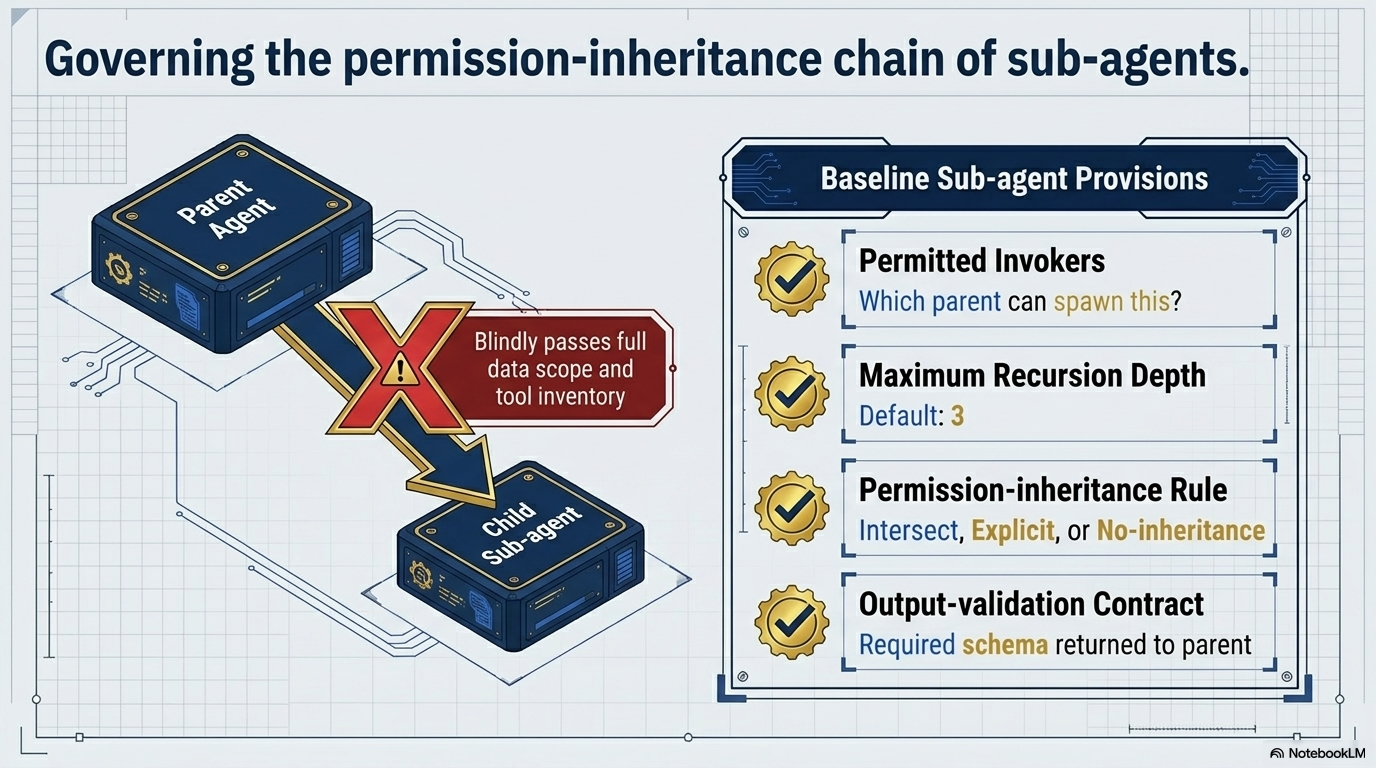
Sub-agent Provisions. Four extra fields a sub-agent’s baseline must carry to close the permission-inheritance failure mode: permitted invokers, max recursion depth, permission inheritance rule, output validation contract.
Tier 1 / 2 / 3. The three levels of KRI escalation. Tier 1: warning, investigate within 24 hours. Tier 2: action, auto-throttle and human review. Tier 3: intervention, kill-switch and rollback.
What comes next
If the terms above feel useful, the next post in the series goes deep on the latency gap and the structural reasons observability cannot close it. After that, the framework’s four disciplines, the KRI tier model in detail, the NIST AI RMF crosswalk, a bonus post on Microsoft’s Agent Governance Toolkit, and the AIGP Body of Knowledge mapping as the series closer. A follow-up implementation walkthrough of the framework in the Prism dashboard publishes separately once the dashboard’s agent monitoring extension is live.
Read this primer once. Reference the glossary as needed. The disciplines work whether or not the vocabulary is universal — but the vocabulary is what allows two practitioners to write down what they mean and have it mean the same thing the next morning.
This is part 0 of a six-part series on Configuration Management for AI Agents. Part 1 stakes out the latency gap. Part 2 introduces the four-discipline framework.
Sources cited
Financial-services lineage:
- Federal Reserve, SR 11-7: Supervisory Guidance on Model Risk Management. federalreserve.gov/supervisionreg/srletters/sr1107.htm
- OCC, Bulletin 2011-12. occ.gov/news-issuances/bulletins/2011/bulletin-2011-12.html
AI governance standards:
- NIST, AI Risk Management Framework 1.0. nist.gov/itl/ai-risk-management-framework
- ISO/IEC 42001:2023. iso.org/standard/81230.html
- EU AI Act (Regulation (EU) 2024/1689). artificialintelligenceact.eu/the-act
- IAPP, AIGP Body of Knowledge v2.1. iapp.org/certify/aigp
Runtime layer (referenced for integration patterns):
- Microsoft, Agent Governance Toolkit. github.com/microsoft/agent-governance-toolkit
- Palo Alto Networks, What is Agentic AI Governance? Cyberpedia entry. paloaltonetworks.com/cyberpedia/what-is-agentic-ai-governance
- GitAgent. github.com/open-gitagent/gitagent
Want the Framework Reference?
The Prism CM-AI Framework is documented in a single canonical reference with the four disciplines, the KRI tier definitions, and the standards crosswalks. We share it under NDA with organizations actively scaling AI agent deployments.
Request the Framework Reference